
从零开始的机器学习实用指南(一):机器学习概览

大家好,这里是Duduru,接下来专栏里介绍的是,《Hands on Machine Learning with Machine Learning with Scikit-Learn and TensorFlow》。这本书从实用角度介绍了机器学习,深度学习许多有关的知识。
许多人听到机器学习,都会想到一个机器人管家或者《终结者》里可怕的杀手。但是机器学习并非是幻想,它已经被我们应用几十年了。例如光学字符识别(OCR)或者垃圾邮件过滤器。后来出现的更多的机器学习产品,影响着我们的方方面面,从推荐系统到语音识别等。
什么是机器学习
机器学习是通过编程让计算机从数据中进行学习的科学(和艺术)。
一个更广义的概念是
机器学习是无需进行明确编程,就能让计算机具有学习的能力。 —— Arthur Samuel,1959
和一个工程性的概念:
机器学习是程序利用经验 E,来进行学习任务 T,并且用性能 P进行度量,任务 T 的性能度量 P 随着经验 E 不断增长。—— Tom Mitchell,1997
以一个垃圾邮件过滤任务为例,它可以从垃圾邮件和普通邮件的例子中学习标记垃圾邮件。任务 T 就是标记新邮件是否是垃圾邮件,经验E是训练数据,性能度量P需要定义:如,准确率。而如果只是下载维基百科,就算电脑里有很多数据,但是不能提升某个任务的表现,因此这不是机器学习。
为什么要用机器学习
还是以垃圾邮件过滤为例:
如果你采用一些传统方法,可以捕捉一些垃圾邮件里的规律,比如包含着“信用卡”,“免费”等等字样,就大概率是一个垃圾邮件。
如果检查到包含这些规律,就识别为垃圾邮件。然后测试你的程序-分析错误-发现新的规律-再测试。直到你的程序已经足够好。
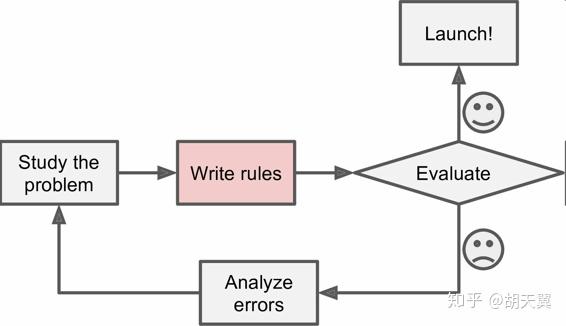

这样的问题是,规律可能被总结的很长,导致维护起来很困难。比如“4U”的邮件都被屏蔽了,那些发垃圾邮件的人可能会转而使用“For U”。使用传统方法,如果发送垃圾邮件的人持续更改,你就需要被动地不停地写入新规则。基于机器学习的垃圾邮件过滤会自动识别新的特征,然后就能自动标记垃圾邮件而无需干预了。
对比起来,机器学习分析垃圾邮件与普通邮件,检测垃圾邮件中反常频次的词语格式。这个程序短得多,更易维护,也更精确。
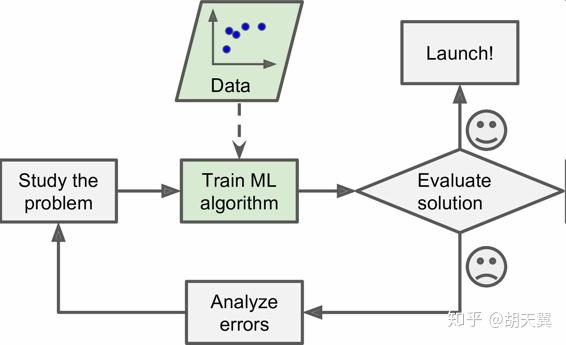

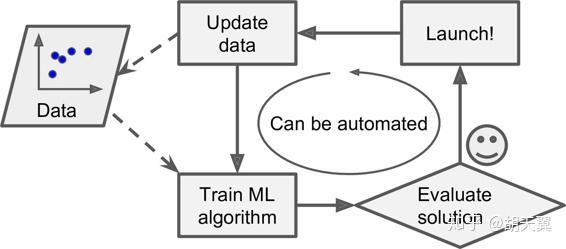
机器学习还可以解决传统方法因为太复杂难以解决的问题。类似于识别声音“One”,不同的环境下可能有成千上万种不同的声音,这是很难完成的。但是机器学习可以学习得到如何识别
最后,机器学习可以帮助人们来学习,使用机器学习方法挖掘大量数据,可以发现并不显著的规律。这称作数据挖掘。
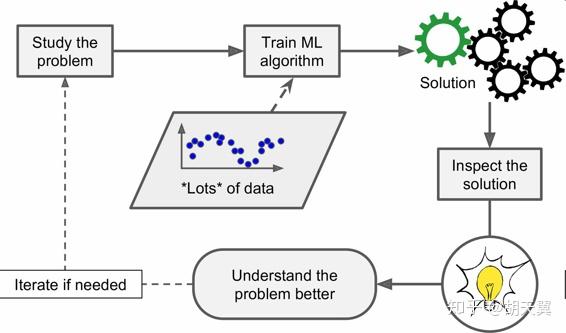
总结来说,机器学习有以下优点
- 对于复杂的问题,可以大大减少人工操作量,简化代码,提高表现。对于传统方法难以解决的问题可以给出解决方案。
- 可以适应数据的变化
- 可以洞察大量的数据和复杂的问题。
机器学习的种类
根据不同的规则,可以有不同的划分:
- 是否在人类的监督下训练(监督学习,无监督学习,半监督学习,强化学习)
- 是否动态渐进学习(在线学习 vs 批量学习)
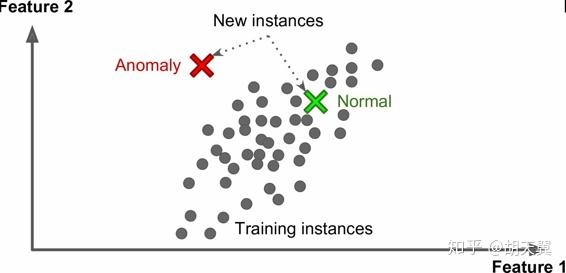
- 是否通过简单地比较新的数据点和已知的数据点,还是学习建立一个预测模型(基于实例学习 vs 基于模型学习)
监督学习vs无监督学习
监督学习的训练数据包含了对应问题的答案,称为标签
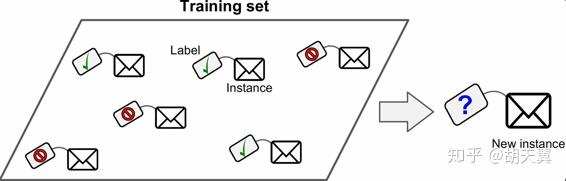

一个典型的监督学习任务是分类。例如垃圾邮件过滤器。另一个典型任务是预测目标数值,例如预测售价。但是一些回归算法也可以用来进行分类,反之亦然。例如,逻辑回归通常用来进行分类,它可以生成一个归属某一类的可能性的值(例如,20% 几率为垃圾邮件)。
在无监督学习中,训练数据是没有标签的。系统在没有老师的条件下进行学习。
例如,你有你的博客访问者的许多信息,你可以使用聚类算法来检测相似访客的分组。你不需要告诉算法访客是哪一类的,算法会自动发现某些关系而无需人类的帮助,例如:40%的访客是漫画爱好者。
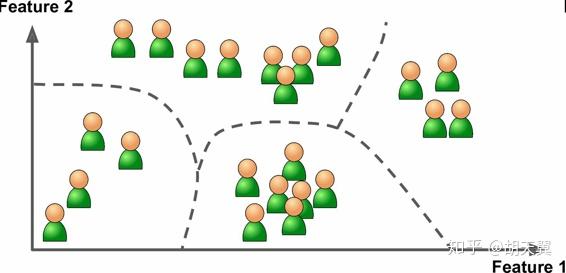

一些可视化方法也是无监督学习很好的例子,你投喂一些复杂的数据,算法可以给出2D或者3D图像。算法会尽可能保留原有的结构(如LDA,让不同类别的信息降维后减少重叠)这样你可以很容易理解数据并且可能发现一些规律。
相关的任务是降维,降维目的是简化数据同时不丢失大量的信息。一种方法是可以合并相关的特征,如汽车的里程和汽车的车龄,可以被合并为一个特征,这叫做特征抽取
在训练许多机器学习算法之前,尤其是特征很多的时候,都可以对数据进行降维,这样可以让程序变得更快,节省内存和磁盘空间,有时还会提升表现。
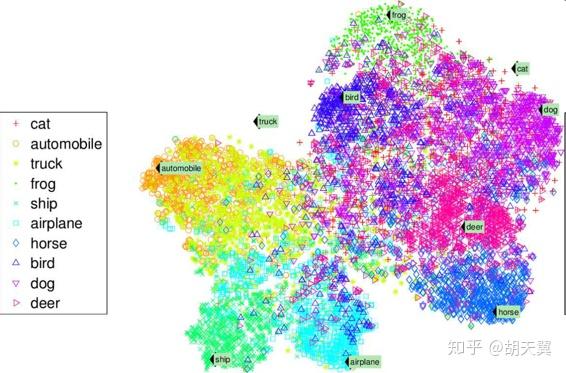

另一个重要的无监督学习是异常检测,比如检测异常的信用卡转账来防止诈骗,检测缺陷或者从数据集剔除异常的值。异常检测可以用正常值训练,当看到一个新的例子,就可以识别是正常值还是异常值。

最后,一个常见的无监督学习是关联规则学习。它挖掘大量的数据来发现一些有趣的关系。比如买了薯片的人也常常会买牛排,因此商家可以把他们放在一起。
半监督学习可以处理一部分有标签的数据,常常是大量的无标签数据和一小部分有标签的数据。
比如谷歌照片,可以用无监督的部分(聚类)识别出1,2,5照片是同一个人,这样,如果你在某一张照片上传了这个人是谁,就可以标记这一类所有的照片,可以便于搜索。
多数半监督学习算法是无监督和监督算法的结合。例如,深度信念网络(deep belief networks,DBN)是基于被称为互相叠加的受限玻尔兹曼机(restricted Boltzmann machines,RBM)的非监督组件。RBM 是先用无监督方法进行训练,再用监督学习方法进行整个系统微调。
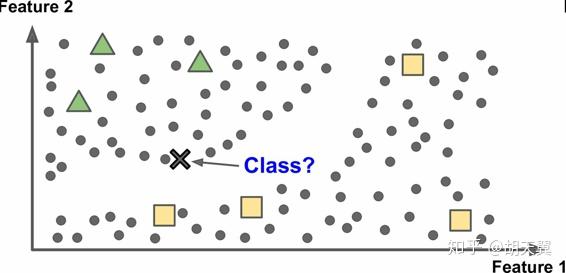

强化学习和前面的不同,学习系统在这里被称为智能体(agent)。可以观察环境,选择和执行操作,获得奖励(惩罚是一种负奖励)。来学习哪个是最好的策略(policy)。策略决定了智能体在给定的环境下应该选择什么行动。

例如,许多机器人用强化学习算法以学习如何行走。AlphaGo 也是强化学习的例子:它击败了李世石和柯洁。它是通过分析数百万盘棋局学习制胜策略,然后自己和自己下棋。要注意,在比赛中机器是不再学习的;AlphaGo 只是使用它学会的策略。
批量学习vs在线学习
批量学习中机器不能持续的学习,机器通常要用很多的时间和资源在线下训练,等模型发布之后就不再训练了只是应用而不再学习新的,这常常被称为离线学习
如果你训练一个批量学习的系统来学习新数据,你必须使用全量的数据,然后把老的系统换成新的。这个过程可以被自动化,因此即使是批量学习,也可以学会适应变化。但是训练的成本有时很大,如果成本开销太大,或者计算资源有限,或者需要更快的响应速度,可能更适合在线学习。
在线学习系统自动接受连续数据流,学习步骤比较快而且成本很低,可以动态学习刚刚到达的数据。对于连续的数据(比如股票价格)或者资源有限,是很不错的方案。
有时数据仍然太大存储不下,可以重复的加载部分数据,直到学习完成,这个过程被称为核外学习(out-of-core learning)。这个过程常常是离线完成的(不在部署的系统上),所以比起“在线”学习,理解为“持续”学习可能更合适。

在线学习的一个参数是,系统多快地适应变化。高的学习速率可以很快的适应变化,但是会忘记老的数据,并且容易被一些坏数据影响。学习慢的系统很慢才能适应变化,但是对新数据噪声抵抗更强一些。
在线学习的一个挑战是坏的数据用来被训练,模型表现会变差。比如来自于失灵的传感器或者恶意攻击。这是需要监测模型的表现,及时的关闭或者回滚到之前的状态,有时还需要对异常点及时做出监测。
基于实例学习vs基于模型学习
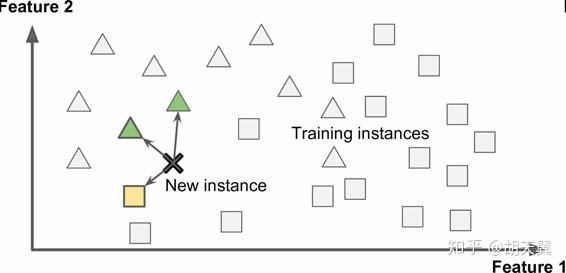
基于实例学习可能最平常的学习方式是利用记忆,以垃圾邮件检测为例,对于一封新的邮件,我们可以靠找到训练数据里和它最相似的,相似性可以被定义为相同单词的个数。
这被称为利用实例学习,系统先记住一些例子,再靠相似度推广到所有的新的例子。

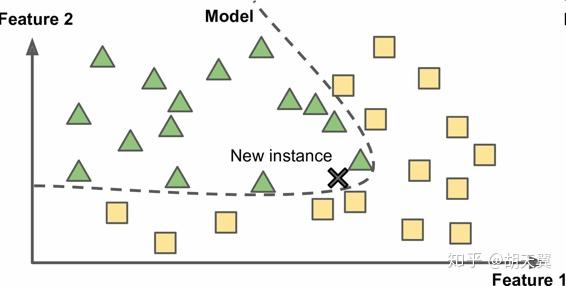
基于模型学习从样本里学习到一个模型,再利用模型进行预测。

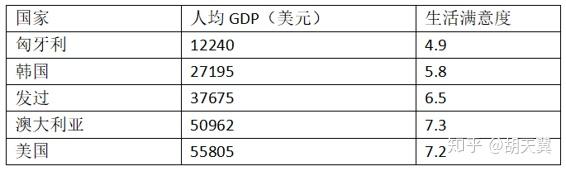
比如我们想知道,钱能让人快乐吗?可以先从 OECD 网站下载了 Better Life Index 指数数据,还从 IMF 下载了人均 GDP 数据。如表:

并且画图:
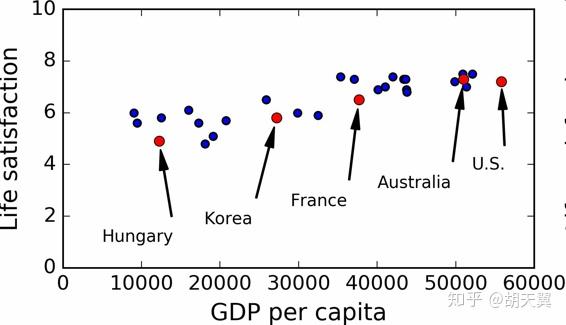

可以发现尽管数据有噪音,但似乎人们越有钱越幸福。可以决定建模一个生活满意程度的线性模型 ,这一步为模型选择。

你可以通过调整参数 \theta_0 和\theta_1 ,表示任何的线性函数,如图


在使用模型之前,需要知道哪个值可以使模型的性能最佳呢?回答这个问题,需要先指定性能量度。对于线性回归问题,人们一般是用代价函数测量线性模型的预测值和训练样本的距离差,目标是使距离差最小。
你用训练样本训练线性回归算法,算法找到使线性模型最适合数据的参数。这称作模型训练。在我们的例子中,算法得到的参数值是 \theta_0=4.85 和 \theta_1=4.91\times 10^{-5} 。


最后,你可以运行模型进行预测了。例如,你想知道塞浦路斯人有多幸福,你可以查询塞浦路斯的人均 GDP,为 22587 美元,然后应用模型得到生活满意度,后者的值在4.85+22587*4.91* 10^{-5} =5.96左右。
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import sklearn
# 加载数据
oecd_bli = pd.read_csv("oecd_bli_2015.csv", thousands=',')
gdp_per_capita = pd.read_csv("gdp_per_capita.csv",thousands=',',delimiter='\t',
encoding='latin1', na_values="n/a")
# 准备数据
country_stats = prepare_country_stats(oecd_bli, gdp_per_capita)
X = np.c_[country_stats["GDP per capita"]]
y = np.c_[country_stats["Life satisfaction"]]
# 可视化数据
country_stats.plot(kind='scatter', x="GDP per capita", y='Life satisfaction')
plt.show()
# 选择线性模型
lin_reg_model = sklearn.linear_model.LinearRegression()
# 训练模型
lin_reg_model.fit(X, y)
# 对塞浦路斯进行预测
X_new = [[22587]] # 塞浦路斯的人均GDP
print(lin_reg_model.predict(X_new)) # outputs [[ 5.96242338]] 在前面的代码中替换线性回归模型为 K 近邻模型,只需更换下面一行:
clf = sklearn.linear_model.LinearRegression()为:
clf = sklearn.neighbors.KNeighborsRegressor(n_neighbors=3)如果顺利,你的模型就可以作出好的预测。如果不能,你可能需要使用更多的属性(就业率、健康、空气污染等等),获取更多更好的训练数据,或选择一个更好的模型(比如,多项式回归模型)。
总结一下,一个典型的机器学习项目的流程是:
- 研究数据
- 选择模型
- 用训练数据进行训练(学习算法搜寻模型参数值,使代价函数最小)
- 最后,使用模型对新案例进行预测(这称作推断),但愿这个模型泛化效果不差
机器学习的主要挑战
数据量的不足
如果教一个小孩子学习认识苹果,可能只需要对着苹果说几次,就可以让他认识所有颜色和种类的苹果了,但是我们的机器学习程序还远远做不到,它需要大量的数据,尤其是类似于语音和图像这种复杂的问题,你可能需要百万级的数据(除非你可以重复利用部分存在的模型)
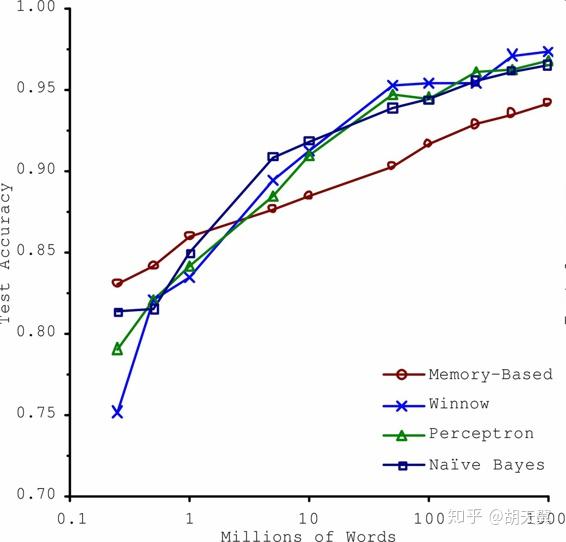

有时候数据量的提升作用远远大于模型之间的差距。我们必须要考虑花时间设计算法还是收集数据的权衡。但是,小型和中型的数据集仍然是非常常见的,获得额外的训练数据并不总是轻易和廉价的,所以不要抛弃算法。
数据没有代表性
例如,我们之前用来训练线性模型的国家集合不够具有代表性:缺少了一些国家。


新模型的实线和旧模型的虚线表示。添加几个国家不仅可以显著地改变模型,它还说明如此简单的线性模型可能永远不会达到很好的性能。可能非常富裕的国家没有中等富裕的国家快乐,而一些贫穷的国家比富裕的国家还幸福。
即使数据集很大,样本可能仍然没有代表性,这是因为训练数据的分布和真实存在着偏差,比如我们采样有些问题。上面的例子中,因为只采用了中等国家,没有考虑非常富裕或者贫穷的国家,就存在明显的问题。
一个著名的例子是, 1936 年兰登和罗斯福的美国大选,《文学文摘》非常有信心地预测兰登会以 57% 赢得大选。然而,罗斯福赢得了 62% 的选票。
- 首先,《文学文摘》使用了电话黄页、杂志订阅用户来调查用户地址,这些地址偏向富裕人群,他们都倾向于投票给共和党(即兰登)。
- 第二,只有 25% 的回答了调研。它排除了不关心政治的人、不喜欢《文学文摘》的人等,这种特殊的样本偏差称作无应答偏差。
低质量数据
显然,如果训练集中的异常和噪声太多,系统检测出潜在规律的难度就会变大,花时间对训练数据进行清理是十分重要的。
- 如果一些实例是明显的异常值,最好删掉它们或尝试手工修改错误;
- 如果一些实例缺少特征(比如,你的 5% 的顾客没有说明年龄),你必须决定是否忽略这个属性、忽略这些实例、填入缺失值(比如,年龄中位数),或者训练一个含有这个特征的模型和一个不含有这个特征的模型,等等。
不相关的特征
如果进来的是垃圾,出去的也是垃圾。机器学习项目成功的关键之一是用好的特征进行训练。这个过程称作特征工程,包括:
- 特征选择:在所有存在的特征中选取最有用的特征进行训练。
- 特征提取:组合存在的特征,生成一个更有用的特征(降维算法可以提供帮助)。
- 收集新数据创建新特征。
接下来是一些算法不好的例子
过拟合
如果你在外国旅游被出租车司机欺诈了,你可能会说这个国家所有的出租车司机都是小偷。过度归纳是人类犯的错误,机器也会犯同样的错误。在机器学习中,这称作过拟合:意思是说,模型在训练数据上表现很好,但是推广到新的数据效果不好。
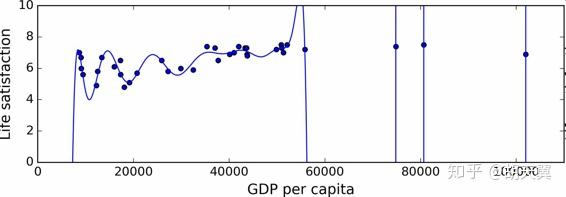

即使上面的高阶多项式拟合的很好,仍然预测起来是很难被信任的。
复杂模型比如深度神经网络,可以检测数据中的细微规律,但是如果训练集有噪声,或者训练集太小(太小会引入样本噪声),模型就会去检测噪声本身的规律。很明显,这些规律不能推广到新的实例。例如,复杂的模型可能会检测出训练集中名字有 w 字母的国家的生活满意度大于 7:新西兰(7.3),挪威(7.4),瑞典(7.2)和瑞士(7.5)。你能相信这个 W-满意度法则推广到卢旺达和津巴布韦吗?很明显,这个规律只是训练集数据中偶然出现的,但是模型不能判断这个规律是真实的、还是噪声的结果。
对于过拟合,可能的解决方案有:
- 简化模型,可以通过选择一个参数更少的模型(比如使用线性模型,而不是高阶多项式模型)、减少训练数据的属性数、或限制一下模型。
- 收集更多的训练数据
- 减小训练数据的噪声(比如,修改数据错误和去除异常值)
限定一个模型以让它更简单,降低过拟合的风险被称作正则化(regularization)。以线性回归为例,如果斜率被限制为0,模型会变得非常简单,如果没有任何限制,模型能完美拟合训练数据,而你的目标是在完美拟合数据和保持模型简单性上找到平衡,确保算法的推广效果。
正则化的度可以用一个超参数(hyper-parameter)控制。超参数是一个学习算法的参数(而不是模型的)。这样,它是不会被学习算法本身影响的。调节超参数是创建机器学习算法非常重要的一部分(下一章你会看到一个详细的例子)。
欠拟合训练数据
欠拟合是和过拟合相对的:当你的模型过于简单时就会发生。例如,生活满意度的线性模型倾向于欠拟合;现实要比这个模型复杂的多,所以预测很难准确,即使在训练样本上也很难准确。
解决这个问题的选项包括:
- 选择一个更强大的模型,带有更多参数
- 用更好的特征训练学习算法(特征工程)
- 减小对模型的限制(比如,减小正则化超参数)
测试和验证
要知道一个模型推广到新样本的效果,唯一的办法就是真正的进行试验。但如果模型的性能很差,就会引起用户抱怨 —— 这不是最好的方法。
更好的选项是将你的数据分成两个集合:训练集和测试集。通过模型对测试集的评估,你可以预估这个错误。这个值可以告诉你,你的模型对新样本的性能。
如果训练错误率低,但是测试错误率高,意味着模型对训练数据过拟合。
假设你在很多模型之间犹豫不决,如何做决定呢?一种方法是都训练,假设你发现最佳的超参数的推广错误率最低,比如只有 5%。然后就选用这个模型作为生产环境,但是实际中性能不佳,误差率达到了 15%。发生了什么呢?
答案在于,你在测试集上多次测量了推广误差率,调整了模型和超参数,以使模型最适合这个集合。这意味着模型对新数据的性能不会高。
这个问题通常的解决方案是,再保留一个集合,称作验证集合。用训练集和多个超参数训练多个模型,选择在验证集上有最佳性能的模型和超参数。当你对模型满意时,用测试集再做最后一次测试,以得到推广误差率的预估。
为了避免“浪费”过多训练数据在验证集上,通常的办法是使用交叉验证:训练集分成互补的子集,每个模型用不同的子集训练,再用剩下的子集验证。一旦确定模型类型和超参数,最终的模型使用这些超参数和全部的训练集进行训练,用测试集得到推广误差率。
没有免费午餐公理
在一篇 1996 年的 著名论文中,David Wolpert 证明,如果完全不对数据做假设,就没有理由选择一个模型而不选另一个。这称作没有免费午餐(NFL)公理。对于一些数据集,最佳模型是线性模型,而对其它数据集是神经网络。没有一个模型可以保证效果更好(如这个公理的名字所示)。确信的唯一方法就是测试所有的模型。因为这是不可能的,实际中就必须要做一些对数据合理的假设,只评估几个合理的模型。例如,对于简单任务,你可能是用不同程度的正则化评估线性模型,对于复杂问题,你可能要评估几个神经网络模型。
文章被以下专栏收录
