未来十年,机器学习的研究热点是什么?
5 个回答

我认为下面这几方面的研究再未来十年会热门,不敢说这几点是不是未来十年最热门的,但一定是热度不减的:
保护隐私的AI技术
目前AI技术的发展需要大量的数据,而另一方面,在现实中个人数据开放必然会导致数据泄露的风险。2018-2019,欧盟出台了GDPR,中国出台《数据安全管理办法》,使用保护隐私的AI技术势在必行。保护隐私的算法很早就提出了,并且得到某些大型互联网公司的应用。
目前使用较广泛的隐私保护的AI技术是联邦学习技术 [1]。联邦学习是是一种分布式机器学习技术,具体原理可以参考 [1],架构如下:
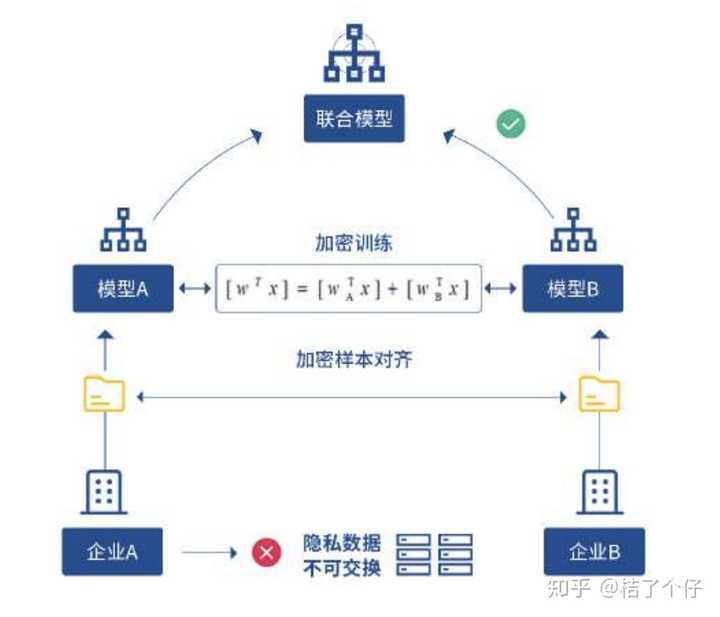

联邦学习在保护隐私方面,目前主要的工具包括:
- 安全多方计算。优点在于可以保证知识在信息层面的数据安全,缺点在于信息传输量大。
- 私密共享。需要信任第三方的存在,优点在于计算效率比较高,而缺点在于由于需要做多次的传输。信息传输效率低。
- 同态加密。优点在于对所有数据进行加密处理,参与方们接收到的是密文,无法推理出原始数据信息,缺点是计算效率低。在实际中,为了提高效率,参与方一般采用半同态加密。
- 差分隐私。优点在于保证数据信息的安全。参与方在各自的原始数据上不断添加噪音,从而减弱任意一方数据对于整体数据的影响,缺点也显而易见,过多的噪音会降低模型训练的效果,从而降低效果,因此参与方使用差分隐私时,需要在数据安全和准确度上做取舍。研究表明,在联邦学习中,如果参与方数量较少,用差分隐私来进行数据的隐私保护,模型的准确率会较低。
事实上联邦学习并不是新技术,但由于联邦学习目前并不完美,效率低是最大缺点。然而隐私保护势在必行,所以未来十年,我相信会有更多关于保护隐私的机器学习架构出现,相关研究也是一个热点。
大规模图神经网络
2019年可以说是图神经网络元年。2019-2020年之间,图神经网络成为各大顶会的增长热词。工业界的动作也非常迅速,2019年初阿里开源工业级图深度学习框架 Euler和AliGraph。

我个人对图神经网络的研究并不深入,但我根据他人的研究成果了解到,大规模图神经网络将端到端学习与归纳推理相结合,有望解决深度学习无法处理的关系推理、可解释性等一系列问题。
虽然还有的说法是”强大的图神经网络将会类似于由神经元等节点所形成网络的人的大脑,机器有望成为具备常识,具有理解、认知能力的AI“,但我觉得十年内就要达成这个成果恐怕不太行。我刚好前几天写过相关回答。
量子计算机上的机器学习
对于这一点,其实我是持不确定态度的。并不是觉得量子计算机不行,而是觉得十年可能不太够。
Tensorflow在3月份发布了2.2版本,其中发布了量子计算的机器学习架构TF Quantum
在计算机中单位是bit,而量子是Qubit,表示各方向上的状态。

TF Quantum的使用其实也不难。


不过除了机器学习框架,更重要的是寻找专用级的芯片,用它来解决特定行业的问题。未来十年应该会有个研究的热度,但产出可能有限,还是需要多点耐心给这个领域。
参考
- ^ a b联邦学习白皮书 https://aisp-1251170195.cos.ap-hongkong.myqcloud.com/wp-content/uploads/pdf/%E8%81%94%E9%82%A6%E5%AD%A6%E4%B9%A0%E7%99%BD%E7%9A%AE%E4%B9%A6_v2.0.pdf

写在前面
个人认为,隐私保护机器学习可占一席。
何为隐私保护机器学习呢? 在这里,引用本人隐私计算专栏中的一篇文章。想学习和了解隐私保护机器学习的朋友,记得关注我,我会持续给大家带来最前沿的理论和实践知识。
隐私保护机器学习作为未来 AI 发展的底层技术,它依靠安全可信的数据保护措施下连接数据孤岛的模式,将不断推动全球 Al技术的创新与飞跃。
随着隐私保护机器学习在更大范围和更多行业场景的渗透及应用,它在更高层面上对各类人群、组织、行业和社会都将产生巨大影响,联邦学习的公共价值主要体现在以下几个方面∶
- 加速人工智能技术创新发展
- 保障隐私信息及数据安全
- 促进全社会智能化水平提升

何为隐私保护机器学习
如图1所示,考虑以下场景时:一组数据属主 (他们可能是半诚实的,甚至是恶意的) 计划在他们拥有的数据上联合训练一个机器学习模型,并提供安全保证(只考虑安全训练阶段,忽略安全推断)。 请注意,这里的重点是安全训练阶段,这是更通用的,因为在进行训练时,安全推断自然是隐含的。 这些数据属主在训练期间与 (或不与) 集中式服务器通信。 但是,它们不会将原始数据上传到集中服务器(或其他数据属主)。
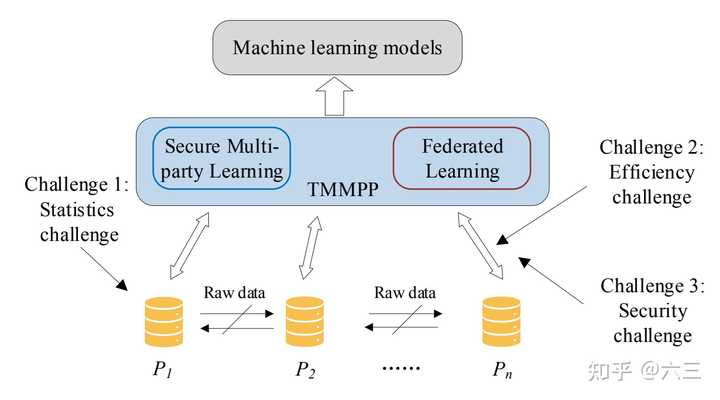

在此,提出了上述问题的形式化定义,在不失一般性的前提下:
假设 \{\mathcal D_1,\mathcal D_2,...,\mathcal D_n\} 分别为 n 个数据属主 \{\mathcal P_1,\mathcal P_2,...,\mathcal P_n\} 所持有的原始数据集,它们可能是相互不信任的。 \mathcal M 表示数据属主合作训练的机器学习模型。
Input:每个数据属主 \mathcal P_i 以其拥有的原始数据 \mathcal D_i 作为输入。
Output:由所有数据属主联合训练的全局模型 \mathcal M (在训练过程中不将任何数据属主的原始数据的任何信息暴露给其他实体)。
基本上,我们假设网络是可靠的,系统是同构的。 具体来说,在 MPL 的解决方案中,一组数据属主协同计算其输入上的函数,除了计算结果外,不透露任何信息,包括中间结果。此外,MPL 方案可以潜在地保持模型的私密性。
在FL的方案中,目的是在约束条件下学习全局机器学习模型,每个数据属主的数据都在本地存储和处理,只有模型参数通过中心化服务器进行通信。集中式服务器和数据控制器都可能不被信任。
需要注意的是,在本文中,MPL 和 FL 两个类解决方案中涉及的数据控属主都是输入方和计算方。但是,在 MPL 的解决方案中,还有其他的设置,可以将计算外包给少量的计算方。而在FL 的实际业务场景中,一个数据属主可能会将自己的数据私自保存,但获得了训练好的模型,即这个数据属主不是计算方。
大家可能对MPL和FL不太熟悉,我简单介绍下作者的意思
本文从两种技术方案出发,深入研究了目前在多个数据源上训练机器学习模型(Training machine learning Models over Multiple data sources with Privacy Preservation,简称TMMPP)问题的进展。
1)安全多方学习(简称MPL),即基于安全多方计算(简称MPC)的机器学习,其架构通常是Peer-to-Peer模型。
2)联合学习(Federated Learning,简称FL),其架构典型的是客户端-服务器模式。
隐私保护机器学习挑战
当我们解决 TMMPP 问题时,会面对以下三个挑战。
- 统计挑战
- 效率挑战
- 安全挑战
2.1 统计挑战
数据属主所掌握的数据通常是以非IID(not independent and identically distributed)的方式产生或收集的,即数据可能不是独立的,或者有明显的分布差别,甚至既不独立也不相同分布。
此外,分布在各数据属主之间的数据量也可能有很大差异,换句话说,数据是不平衡的。非IID和不平衡的数据使得训练一个高质量的机器学习模型变得困难,并且可能会增加分析、评估的复杂性。例如,占总数据量很大一部分的数据属主,在集中式服务器聚合模型参数的阶段会起到决定性的作用,从而影响模型的性能。
2.2 效率挑战
效率是TMMPP的重要瓶颈,包括通信开销和计算复杂性。在多个数据源上训练机器学习模型,涉及到大量的数据属主 (例如在FL的场景中,就有数百万个数据属主)。由于保护每个数据主隐私的安全要求,它们之间的通信带来了额外的开销,相比于原始数据的本地计算,开销增加了很多数量级。
此外,在MPL框架中,通信和计算的成本很大程度上取决于底层协议。例如,基于HE的协议通常会导致较高的计算复杂度,而基于GC的协议通常会导致昂贵的通信开销。一般来说,为了提高MPL框架的效率,应该在通信开销和计算复杂度之间进行权衡。
2.3 安全挑战
每个数据控属主和集中式服务器都不能完全信任。 他们中的一些人可能是 adversaries,他们可以以某种方式对私人信息进行攻击或干扰训练算法的正常执行。
此外,FL通过交换模型参数(例如局部梯度)而不是原始数据来保护每个数据控制器的数据。 然而,如果对这些梯度进行推算操作,这些梯度可能会泄漏原始数据的敏感信息,从而导致集中式服务器在聚合这些梯度过程中的隐私泄漏。
三、隐私保护机器学习框架
一、框架分类
考虑到机器学习训练过程中使用的基本技术,将MPL框架分为四类,包括:
- 基于HE的MPL框架;
- 基于GC的MPL框架;
- 基于SS的MPL框架;
- 基于混合协议的MPL框架。
二、安全多方学习
以下是几种MPC协议和MPL框架,它们利用HE、GC和SS等一种或多种密码原语来训练具有隐私保护的多方机器学习模型。 每个密码原语都提供了自己的特性和权衡,因此基于它们的框架也有相应的优点和缺点。
2.1 基于HE的MPL框架
HE是一种加密形式,人们可以直接对密文执行特定的代数操作,而不解密它,也不知道任何关于私钥的信息。 然后,它生成一个加密结果,其解密结果与在明文上执行的相同操作的结果完全相同。
HE可以分为三种类型的。部分同态加密(PHE)只允许无限次的一种操作(加法或乘法)。为了在密文中同时进行加法和乘法,可以使用有限同态加密(SWHE)和全同态加密(FHE)。SWHE可以在有限次数内执行某些类型的操作,而FHE可以在无限次数处理所有操作。FHE的计算复杂度比SWHE和PHE要昂贵得多。
这里的介绍有点啰嗦了,毕竟关注我的小伙伴,已经在我FHE专栏文章中,深入了解了FHE的知识。但是呢,应该有很多新小伙伴,所以这里介绍的还是会详细一点。
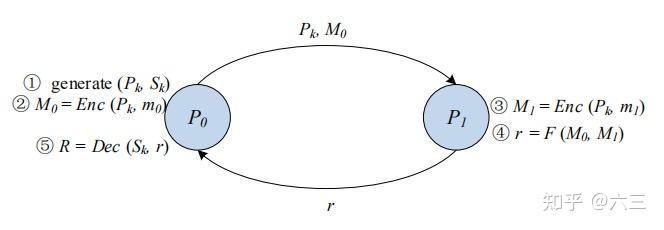
通过直接对加密数据进行计算,HE可以用来保证计算过程的安全性。当然,在训练机器学习模型时,可以采用HE直接对加密文本进行计算和通信,以保护数据隐私。这里,如图1所示,以安全的两方计算为例,一方 P_0 生成同态密码系统的密钥对 (P_k, S_k) ,并将公钥 P_k 连同他的加密信息 M_0 发送给另一方 P_1 , P_1 再利用密码系统与 M_0 的同态特性评估加密下的算术电路。最后, P_1 发回加密结果 r ,P_0 可以用其私钥解密。这样一来,未加密的数据本身并没有被传输,也不能被其他方猜到,只有一点泄露原始数据的可能。此外,HE 方法被广泛应用于MPL框架中,在预计算阶段生成乘三元组[1],可以有效降低在线阶段的通信开销。需要注意的是,非线性函数如ReLU、Sigmod激活函数不能被HE所支持。
虽然提前说好了,不做主观评论,但还是想提一句,这里说的HE不支持非线性函数,是因为在绝大多数MPL中,使用的都是PHE。其实,FHE是可以支持的,不过需要一些技巧。感兴趣的可以去我全同态加密专栏中,查看 "飞马" 相关系列。

2.2 基于GC的MPL框架
GC,又称Yao's 混淆电路,是一种安全的两方计算的底层技术,最初由姚期智院士提出。GC提供了一个交互式协议,让两方(一个混淆者garbler和一个评估者evaluator)对一个任意函数进行无意识的评估,这个函数被表示为一个布尔电路。
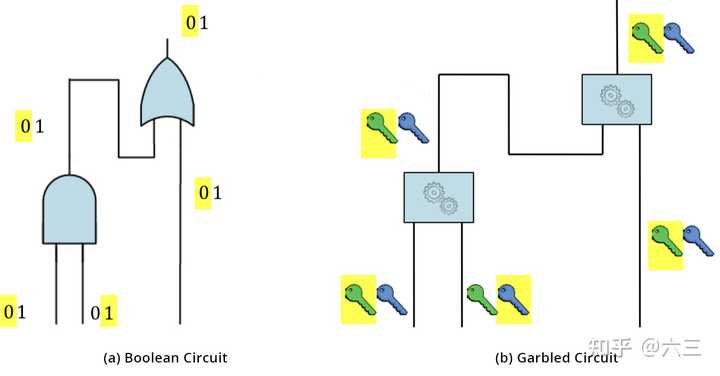

在经典GC的构造中主要包括三个阶段,即加密、传输和评估。
首先,对于电路中的每一条线 i ,garbler 生成两个随机字符串 k_i^0 和 k_i^1 作为标签,分别代表该线可能的两个位值 "0 "和 "1"。对于电路中的每一个门,garbler都会创建一个真值表。真值表的每个输出都使用与其输入相对应的两个标签进行加密。这是由garbler选择一个密钥推导函数,利用这两个标签生成对称密钥。
然后,garbler对真值表的行进行换行。在混淆阶段结束后,garbler将混淆后的表以及与其输入位对应的输入线标签传送给 evaluator。
此外,evaluator通过Oblivious Transfer安全地获取其输入对应的标签。有了混淆表和输入线的标签,evaluator负责对混淆表进行反复解密,直到得到函数的最终结果。
这里的Oblivious Transfer为不经意传输,是另外一个密码学原语,感兴趣的朋友可以去参考文献中学习。对于GC的改进,如果有兴趣的朋友想多了解一些,可以关注并私信我。
2.3 基于SS的MPL框架;
秘密共享SS方案是密码学中的关键工具,在许多安全协议中被用作构建块。 基于SS的协议,如加法SS、Shamir的SS、GMW(Goldreich-Micali-Wigderson)、BGW(Ben-Or-Goldwasser-Wigderson)和SPDZ,适用于多方。 在基于SS的MPL框架中,各方最初使用SS方案将其秘密输入拆分为共享。
2.3.1 GMW
GMW协议是第一个安全的多方计算协议,允许任意数量的一方安全地计算一个可以表示为布尔电路或算术电路的函数。以布尔电路为例,所有各方使用基于XOR的SS方案共享输入,各方交互计算结果,逐门计算。
GMW协议对布尔电路的评估如下:与Yao的GC类似,对于电路中的XOR门,各方可以分别使用SS进行XOR分享。各方的本地计算可以忽略。而对于AND门,评估每个门需要各方之间进行通信,乘法三元组可以使用OT或其扩展进行预计算。因此,GMW协议的性能取决于电路中AND门的总数(OT的数量)和电路的深度。
基于GMW的协议不需要对真值表进行混淆,只需要进行XOR和AND运算进行计算,所以不需要进行对称的加解密操作。此外,基于GMW的协议允许预先计算所有的加密操作,但在在线阶段需要多方进行多轮交互。因此,GMW在低延迟网络中取得了良好的性能。
2.3.2 BGW
BGW协议是3方以上的算术电路安全多方计算的协议。该协议的总体结构与GMW类似。各方最初使用线性SS方案(通常使用 Shamir's SS)共享他们的输入,然后逐门计算结果,其不变条件是各方持有电路内部线值的随机份额。一般来说,BGW可以用来计算任何算术电路。与GMW协议类似,对于电路中的加法门,计算是可以在本地进行的,而对于乘法门,各方需要交互。但是,GMW和BGW在交互形式上有所不同。BGW不是使用OT来进行各方之间的通信,而是依靠线性SS(如Shamir的SS)来支持乘法运算。但BGW依靠的是诚实多数制( honest-majority)。BGW协议可以对抗除 t<n/2 个腐坏方的半诚实敌手,对抗 t<n/3 个腐坏方的恶意敌手。
我在这里将corrupt parties翻译为腐坏方,即可看为被adversaries控制的计算方。
2.3.3 SPDZ
SPDZ是Damgard等人提出的一种不诚实多数制计算协议,它能够支持两方以上的计算算术电路。它分为离线阶段和在线阶段。SPDZ的优势在于昂贵的公钥密码计算可以在离线阶段完成,而在线阶段则纯粹使用廉价的、信息理论上安全的基元。SWHE用于在离线阶段执行constant-round 的安全乘法。SPDZ的在线阶段是linear-round,遵循GMW范式,在有限域上使用秘密共享来确保安全。SPDZ最多可以对抗恶意敌手的 t≤n 个腐坏方,其中 t 为敌手数量, n 为计算方数。
SPDZ系列已然成为了一门学科,每年都有相关的优化方案,读者感兴趣直接阅读[11,12],如果有疑问,欢迎交流。

2.4 基于混合协议的MPL框架。
除了上述单一协议的MPL框架外,一些常用的框架通常采用混合协议,即把两种或多种协议结合起来,以利用每种协议的优点并避免其缺点。例如,将HE和GC结合起来的混合协议的基本思想是:用HE计算具有有效表示为算术电路(如加法和乘法)的运算,用GC计算具有有效表示为布尔电路(如比较)的运算。但是,不同方案的share之间的转换并不简单,成本相对较高。此外,也有一些框架将MPC与差分隐私(简称DP)结合起来。
对于不同方案share之间的转换,大家有兴趣可以直接阅读ABY,ABY3文章,当然还有更新的Trident、BLAZE。
若想了解更多隐私保护机器学习的内容,请关注我,并在我专栏中查看,和我一起学习。

机器学习落地与autoML

经典信号分析方法与机器学习的结合,有可能进一步推高现有机器学习算法的性能。
残差收缩网络就是把(经典信号降噪算法中的)软阈值函数,嵌入到残差网络中,以适用于强噪、高冗余数据的特征学习。
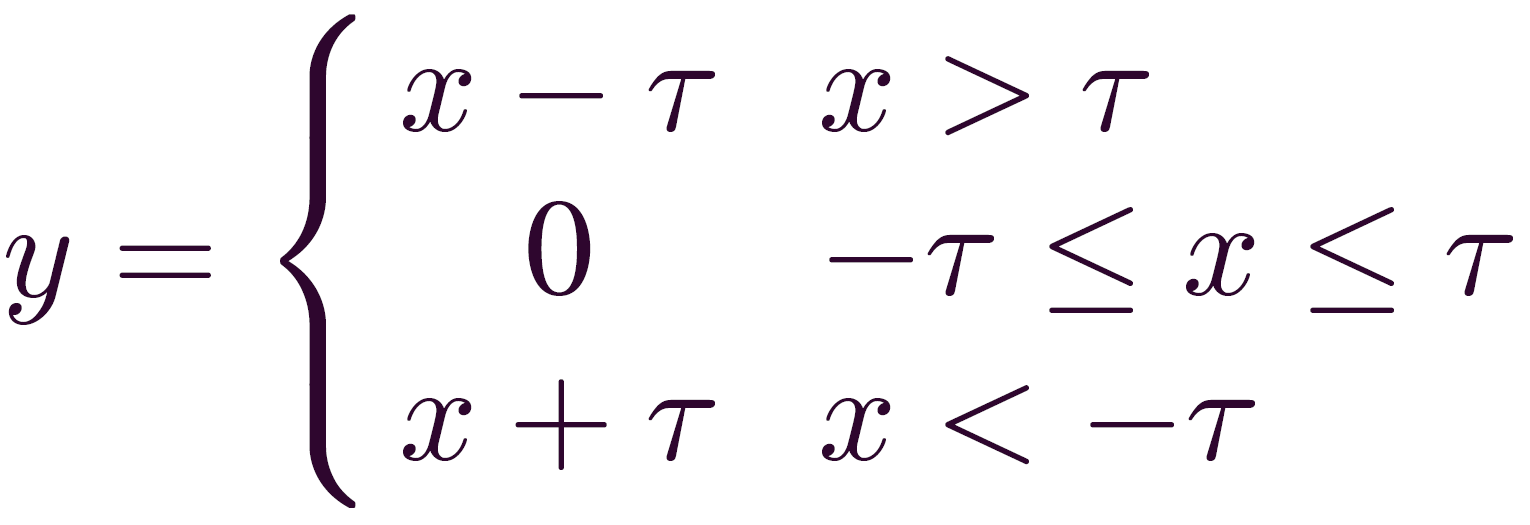

残差收缩网络的结构如下图:
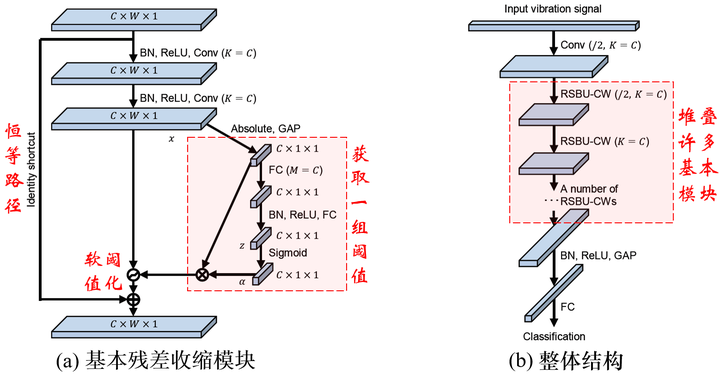

Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.

硬件开发,软件编程是机器人的基础。热点应该是精准硬件的开发。感应器发展是复合型感应器还是单方向高精度感应器我觉得应该齐头并进,在民用上利用复合型感应器。在工业,国防使用单一的高精度感应器。电机的精准度离不开材料。设计。软件编程的问题是一个软件公司的生命力,也就是企业的生命力以及对后续软件开发的支持。科技发展方向性对不对。我们现在的企业一切追求利润。缺少了长期的研发和发展。对于将来很不利。从现在各个行业被卡脖子就能感受到。这于我国一贯的外行指导内行分不开。建议对技术人员进行国家政策的保护于扶持。才能从根本上保证国家持久长效的科技发展力。管理和技术同一个部门的管理人员要做好服务而不是指挥。从根本上解决技术生产制造人员的后顾之忧,才可以说,技术软硬件的研发发展。我作为一个初中教计算机的美术老师的回答,浅知拙见,贻笑大方。