「关键词」提取都有哪些方案?
46 个回答


我们所说的关键词通常由一个或多个 term 组成,即可以是分词后的 term,如“鲜花”、“快递”,也可以是多个 term 组成的 phrase,如“鲜花快递”、“鲜花快递公司”,英文常见叫法是 keyword,keyphrase。
至于什么是关键词呢?至少必须满足两个关键条件:边界合法和有行业区分度。甚至还可以结合具体应用场景增加限制条件,如在计算广告中,还要考虑商业价值。
我们的做法是分两步走:
- 候选词匹配:基于关键词词库的多模式匹配得到候选,这里最重要的工作是词库构建,往往会融合多种方法:垂直站点专有名词,百科词条,输入法细胞词库,广告主购买词,基于大规模语料库的自动词库挖掘(推荐韩家炜团队的 shangjingbo1226/SegPhrase , shangjingbo1226/AutoPhrase 方法)等。这里会涉及大量的数据清洗工作,甚至还可以有一个质量分类器决定哪些词条可以进入词库。
- 候选词相关性排序:包括无监督和有监督方法,如下:
- 无监督方法:常见的有 TFIDF(需要统计 phrase 级别的 DF), textrank(优势不明显,计算量大,慎用),topic 相似度(参见 baidu/Familia),embedding 相似度(需要训练或计算 keyword 和 doc embedding),TWE 相似度(参见 baidu/Familia)
- 有监督方法:常见的有基于统计机器翻译 SMT 的方法(转换成翻译问题,可以采用 IBM Model 1),基于序列标注模型的方法(转换成核心成分识别问题,类似 NER,状态只有0和1,即是否是核心成分,较适用于短文本),基于排序学习LTR的方法(转换成候选词排序问题,采用 pairwise 方法,或者深度语义匹配方法,如 DSSM),基于传统机器学习分类方法(转换成二元或多元分类问题)。
- 有监督方法依赖一定规模的标注数据,效果通常会显著好于无监督方法。
上面的方法仅能抽取文本字面出现的词,会有 Vocabuary Gap 问题,大部分情况下是足够的,还有一种做法可以基于生成模型的方法,自动“抽取”生成一些字面上未出现的词条,如 ACL 2017 Deep Keyphrase Generation( http://memray.me/uploads/acl17-keyphrase-generation.pdf , memray/seq2seq-keyphrase)。另外,也可以考虑基于字面抽取的 keyword,扩展出一些语义相似的词条作为候选词,通过打分排序选出合适的保留下来。
特别的,对于一些存在规律性描述模式的特殊类型文本,如 query log,还可以采用基于 bootstrapping 的软模式匹配方法,通常准确率很高,召回率一般。

我博士阶段的研究课题就是关键词抽取,欢迎下载阅读我的论文“
基于文档主题结构的关键词抽取方法研究”。以我做关键词抽取的经验,建议如下:
1. TFIDF是很强的baseline,具有较强的普适性,如果没有太多经验的话,可以实现该算法基本能应付大部分关键词抽取的场景了。
2. 对于中文而言,中文分词和词性标注的性能对关键词抽取的效果至关重要。
3. 较复杂的算法各自有些问题,如Topic Model,它的主要问题是抽取的关键词一般过于宽泛,不能较好反映文章主题。这在我的博士论文中有专门实验和论述;TextRank实际应用效果并不比TFIDF有明显优势,而且由于涉及网络构建和随机游走的迭代算法,效率极低。这些复杂算法集中想要解决的问题,是如何利用更丰富的文档外部和内部信息进行抽取。如果有兴趣尝试更复杂的算法,我认为我们提出的基于SMT(统计机器翻译)的模型,可以较好地兼顾效率和效果。
4. 以上都是无监督算法,即没有事先标注好的数据集合。而如果我们有事先标注好的数据集合的话,就可以将关键词抽取问题转换为有监督的分类问题。这在我博士论文中的相关工作介绍中均有提到。从性能上来讲,利用有监督模型的效果普遍要优于无监督模型,对关键词抽取来讲亦是如此。在Web 2.0时代的社会标签推荐问题,就是典型的有监督的关键词推荐问题,也是典型的多分类、多标签的分类问题,有很多高效算法可以使用。
1.TF-IDF和关键词提取
作为提取关键词的最基本、最简单易懂的方法,首先介绍下TF-IDF。
判断一个词在一篇文章中是否重要,一个容易想到的衡量指标就是词频,重要的词往往会在文章中多次出现。但另一方面,不是出现次数多的词就一定重要,因为有些词在各种文章中都频繁出现,那它的重要性肯定不如那些只在某篇文章中频繁出现的词重要性强。从统计学的角度,就是给予那些不常见的词以较大的权重,而减少常见词的权重。IDF(逆文档频率)就是这个权重,TF则指的是词频。
TF=(词语在文章中出现次数)/ (文章总词数)
IDF=log (语料库文档总数/(包含该词的文档数+1))
TF - IDF = TF * IDF
摘取一个博客中的一个例子[1]
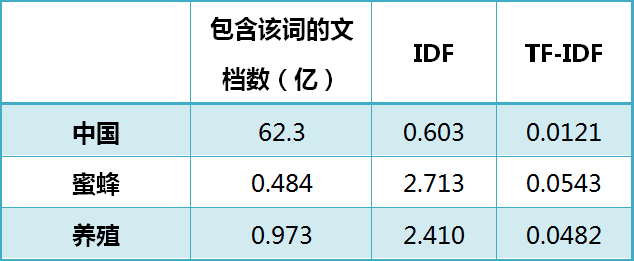

“中国”在文章中的频率并不比“蜜蜂“和”养殖“低,但因其在各种文章中都会频繁出现,因此其逆文档频率较低,不会被识别成本文的关键词。
TF-IDF虽然非常简单,但却很经典有效,而且速度很快,有的场景中会提升第一段和最后一段的文本权重,因为文章的关键词往往会在开头和结尾段频繁出现。但TF-IDF只是仅从词频角度挖掘信息,并不能体现文本的深层语义信息。
2.topic-model和关键词提取
如果说TF-IDF只能从词频角度挖掘信息,那么如何挖掘更深层次的信息呢?这就是topic-model想要完成的任务。
举个例子,以下四个句子:
1.I ate a banana and spinach smoothie for breakfast
2.I like to eat broccoli and bananas.
3.Chinchillas and kittens are cute.
4.My sister adopted a kitten yesterday.
仅从词语角度分析,1.2句banana是重复出现的,3.4句kitten是重复出现的。但其实可以发现1.2句主要跟食物有关,3.4句主要跟动物有关,而food、animal两个词在四句话里均未出现,有没有可能判断出四句话中所包含的两个主题呢?或者当两篇文章共有的高频词很少,如一篇讲banana,一篇讲orange,是否可以判断两篇文章都包含food这个主题呢?如何生成主题、如何分析文章的主题,这就是topic-model所研究的内容。对文本进行LSA(隐形语义分析)。
在直接对词频进行分析的研究中,可以认为通过词语来描述文章,即一层的传递关系。
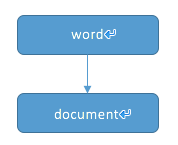
而topic-model则认为文章是由主题组成,文章中的词,是以一定概率从主题中选取的。不同的主题下,词语出现的概率分布是不同的。比如”鱼雷“一词,在”军事“主题下出现的概率远大于在”食品”主题下出现的概率。即topic-model认为文档和词语之间还有一层关系。
首先假设每篇文章只有一个主题z,则对于文章中的词w,是根据在z主题下的概率分布p(w|z)生成的。则在已经选定主题的前提下,整篇文档产生的概率是\prod_{w}p(w\vee z)
而这种对每篇文章只有一个主题的假设显然是不合理的,事实上每篇文章可能有多个主题,即主题的选择也是服从某概率分布p(t)的因此根据LDA模型,所有变量的联合分布为
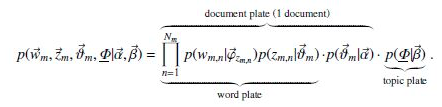

\varphi 表示topic下词的分布,\theta 表示文档下topic的分布。N_{m} 是第m个文档的单词总数。\alpha 和\beta 表示词语和topic的概率分布先验参数。而学习LDA的过程,就是通过观察到的文档集合,学习\varphi,\theta ,z的过程。学习过程参见论文[2]。
下图为一个LDA学习结果的例子
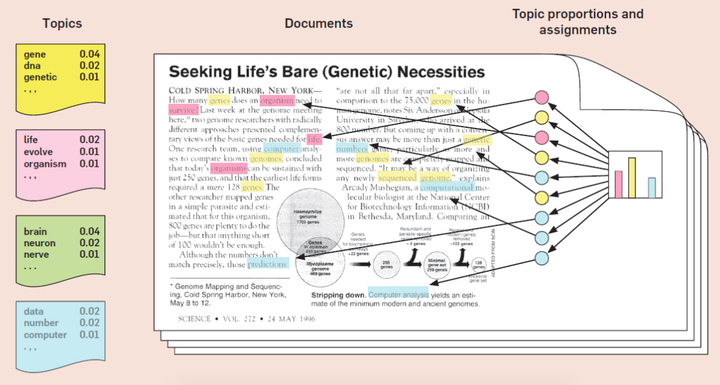

取自[3]
可以看出,topic-model的目的就是从文本中发现隐含的语义维度,在词语和文档之间加入更概括的信息。
3.textrank关键词提取
textrank的则从图模型的角度找文章的关键词,好处在于不用事先基于大量数据进行训练。
其基本思想来自于pagerank算法,pagerank的两条基本思想是,如果一个网页被很多其他网页链接到,说明这个网页比较重要;如果一个网页被一个权值很高的网页链接到,则其重要性也会相应增加。
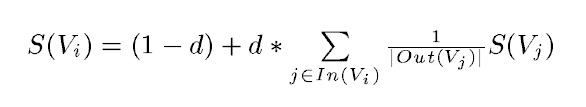

判断两个网页之间是否有边相连,根据网页中出现的链接,而在textrank中判断两个词间是否存在相关关系,则根据词语的共现关系。实际处理时,取一定长度的窗,在窗内的共现关系则视为有效。
修改的textrank算法
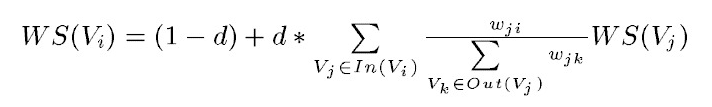

4.rake关键词提取
rake算法提取的并不是单一的单词,而是由单词组成的短语。短语的分割由标点符号

每个短语的得分由组成短语的词累加得到,而词的得分与词的度与词频有关
Score=\frac{degree}{frequency}当与一个词共现的词语越多,该词的度就越大。

算法本身很简单也很好理解,也有可直接供使用的python代码:
GitHub - aneesha/RAKE: A python implementation of the Rapid Automatic Keyword Extraction
参考文献
[1] TF-IDF与余弦相似性的应用(一):自动提取关键词
[2] Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J]. Journal of machine Learning research, 2003, 3(Jan): 993-1022.
[3] Blei D M. Probabilistic topic models[J]. Communications of the ACM, 2012, 55(4): 77-84.
[4] Rose S, Engel D, Cramer N, et al. Automatic keyword extraction from individual documents[J]. Text Mining, 2010: 1-20.

1、前言
关键词抽取(keywords extraction)也称关键短语抽取(keyphrase extraction),一直是数据挖掘领域(data mining)的一个热点。传统的方法如TF-IDF,TextRank,再到序列模型CRF,Bi-LSTM+CRF、BERT+CRF等。前者属于无监督方法,后者是有监督抽取。近年来,随着生成模型的发展,利用生成方式从文本产生新的关键词也成为一个研究热点。今天就这个方向,分享一篇关于文本中关键词抽取与生成的论文—— Select, Extract and Generate: Neural Keyphrase Generation with Layer-wise Coverage Attention。文中的核心思想就是:对于一篇文档来说,比如科学类文献,应该先选择出关键句子,再利用深度模型从这些句子中抽取并生成关键词,而其中利用了一种层级覆盖的注意力机制( Layer-wise Coverage Attention)。
下图为论文中任务及思路的示意:“Present”代表抽取的词,即这些词是在文档中可完整检索出来的;“Absent”代表生成的词,即这些词不在文档中完整存在,但其大部分字是来自文档。而0,1代表对应的句子是否是关键句,而判断的标准就是句子是否存在关键词或者存在关键词中的字。所以,围着这样的任务思路,文中就把解决方法分解成二个步骤:识别文档关键句(Select),基于关键句识别抽取(Extract)present类关键词,并同时生成(Generate)absent类关键词,将两类结合即为最终的结果。这样整个学习任务就包含三个部分:关键句识别(Salient Sentence Selection)、present类关键词抽取(Present Keyphrase Extraction)、absent类关键词生成(Absent Keyphrase Generation)。下面详细介绍三个子任务实现的方法。


2、模型
2.1 关键句识别
对于文档中的关键句识别,论文将其视为一种二分类任务。做法就是将文档切成连续的句子片段,对每个句子进行编码,然后预测概率(0或1)。具体包括:
- 将一个句子按word、char、position,segment四类embedding拼接成最终的embedding E,其中segment代表句子在文档中切分的位置;
- 利用Transformer编码器对上述进行编码,得到编码后的序列向量o;
- 将序列向量o进行最大池化和平均池化,再拼接得到新的句子表征向量s_pool;
- 将新的句子表征向量s_pool对接一个MLP+sigmoid层,做最终的概率预测;
这里要提及的是,论文做的是监督学习,所以可以按前面说的方式判断切分的句子是否为关键句。
2.2 present类关键词抽取
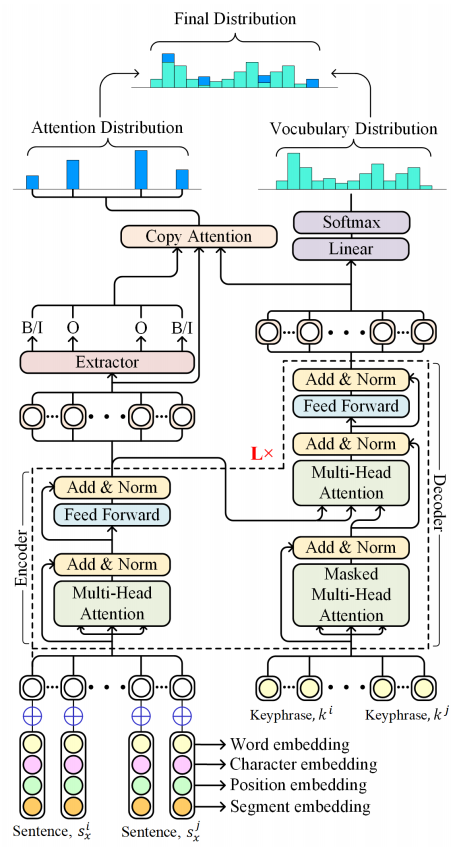

关键词的抽取和生成是同时做的,因为它们可以共用一个编码器Encoder,而编码方式跟上面识别关键句中一样的方式,利用Transformer结构最后得到序列向量o。而present类关键词抽取就可以利用序列向量o上加一个序列预测模型就可实现,是一个NER任务。即为:
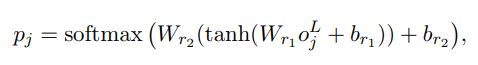

上述p_j代表第j个token属于BIO类标签的概率。
2.3 absent类关键词生成
absent类关键词生成是一个Decoder的过程,也就是上图中右边部分,整过过程也是seq2seq结构。该部分是论文的核心部分。具体来说:
假设Decoder生成了一个absent类关键词序列[y1, y_2, ..., y_m],对应的解码器向量为[h_1, h_2, ..., h_m],即解码的过程可看作一个词分布预测的任务,即vocabulary distribution:
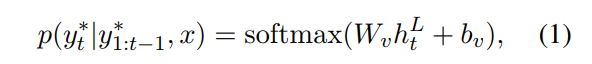

上述也是正常的解码学习过程。此外,为了进一步提升生成效果,文中利用两个attention机制,分别为Coverage Attention和Copy Attention。
Coverage Attention是认为在t时刻生成时,与前面已输入的tokens之间的影响程度不一样的,在解码时应更注重t时刻的输入。该部分作用于解码的过程,即影响解码向量h的学习。对应的权重计算方式如下:
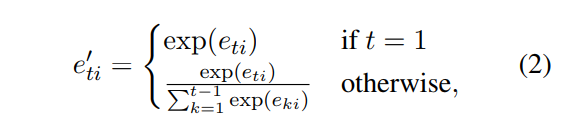

其中e_ti代表target token y_t and the input token x_i 之间的点乘。
Copy Attention是认为在生成的过程中,有些token可以直接从原文复制过来,不用按公式(1)方式去生成。该部分对应模型图中attention distribution。计算方式如下:
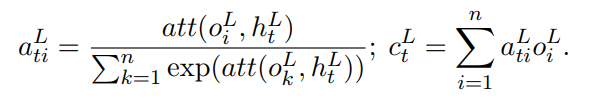

其思路就是计算target token y_t与原序列中o_i关系。而其中a_ti就是表示y_t=x_i复制过来的概率。然后利用c_t和h_t就可以做一个二分类判断,代表复制还是不复制,即为: p(u_t=1)=\sigma(W[h_t,c_t]+b) 。u_t=1代表复制。这样最终的关键词生成分布就变成:
P(y_t)=P(u_t=0)P(y_t|u_t=0)+P(u_t=1)P(y_t|u_t=1)
而当P(y_t|u_t=0)时,计算方式就变成公式(1)。
这样,以上就三个任务的详细实现过程。对应的目标函数分别为常规交叉熵、交叉熵和对数似然函数。
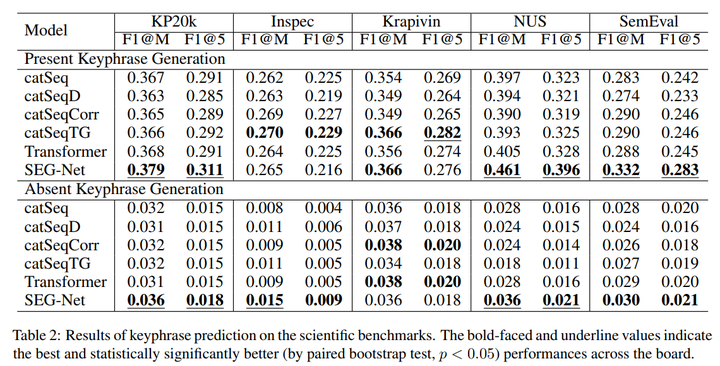
3 实验
实验中选择在科学类文档的5个数据集上进行测试,整体结果如下:文中提出的方法(SEG-Net)在Present和Absent类大部分都有提升。其他实验展示,有兴趣去阅读原文。

4 结语
因为自己最近在做生成相关任务的项目,集中读了十几篇相关文章。觉得关键词生成任务,尤其对搜索引擎优化还是有很大应用价值,就把这篇分享出来。当然,也有几点想法:(1)文章实验的数据集都是人工已标注好的数据,但不确定人工在标注关键词的时候是阅读全文的方式去生成,还是只是利用文章标题和前面几个段落,这样切分并选择关键句来生成与真实目标分布就有差异;(2)生成方式去产生关键词是很有吸引力,但高质量监督数据是一个很大的问题,即使在监督方式下,目前效果应该说也很不理想,而且中文类开源数据集更少很少;(3) 所以,如何无监督或者few-shot的方式去抽取和生成关键词,也很值得去研究的。

关键词提取就是从文本里面把跟这篇文档意义最相关的一些词抽取出来。这个可以追溯到文献检索初期,当时还不支持全文搜索的时候,关键词就可以作为搜索这篇论文的词语。以下是常用的关键词提取的方法:
词数
一个基本的分词筛选方法就是筛掉词数过少的词语,这些词语对大多需求而言更可能是停用词,不论对人工分析还是机器学习都没有意义。该方法可用于对大量的分词结果进行初筛。
tf-idf
tf-idf是常用的对文档或句子中的词语进行打分的方法。某个词的tf-idf取值取决于两个因素:词频以及该词的稀有程度。因此,tf-idf描绘了一个词语在所属文档或句子的独有程度。正因为如此,当我根据tf-idf取top词语构成了关键词集合,它反映的是文档或句子独有的特点,或者说亮点。
tf-idf代表的是同时涉及到词频以及该词稀有度的计算模式,有多钟计算公式,词频最常见的计算方法是改词的出现次数/总词数,词稀有度常见计算方法是对文档总数/含有改词的文档数取对数。可根据需求和实际数据的不同调整词频或词稀有度所占权重。
tf-idf还可用于比较文本相似度,作为文本的特征抽取手段进一步做机器学习。
text-rank
该方法源于page-rank,page-rank是谷歌提出的对网页按照影响力进行排序的算法。同样的,text-rank认为文档或句子中相邻的词语重要性是相互影响的,所以text-rank引入了词语的顺序信息。
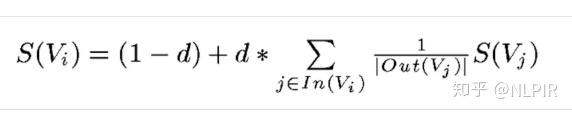

上式中,Vi表示当前要计算权重的词,S(Vi)表示该词的权重,d表示阻尼系数,In(Vi)表示与Vi在同一个窗口的词集合,Out(Vj)表示与Vj在同一个窗口的词集合,|Out(Vj)|表示这个词集合的元素个数。
text-rank算法首先对每个词语的权重进行初始化,然后根据上述公式对每个词语的权重进行更新直至收敛,受em算法理论支持。
text-rank筛选出的top关键词集合最能反应整个文档或句子,与tf-idf不同的是,代表整个文档的词集合并不一定是该文档所独有的,所以如果说要找一个方法进行特征抽取的话,tf-idf显然更加适合。
但是从实用和高效方面推荐一款大数据挖掘工具:NLPIR关键词提取,它能够在全面把握文章中心思想的基础上,提取出若干个代表文章语义内容的词汇或短语,相关结果可用于精化阅读、语义查询和快速匹配等。NLPIR主要采用交叉信息熵计算每个候选词的上下文条件熵,所处理的文档不受行业领域限制,且能够识别出最新出现的新词语,所输出的词语可以配以权重。
NLPIR文章关键词提取的主要特色在于:
1、速度快:可以处理海量规模的网络文本数据,平均每小时处理至少50万篇文档。
2、处理精准:Top N的分析结果往往能反映出该篇文章的主题特征。
3、精准排序:关键词按照影响权重排序,可以输出权重值。
4、开放式接口:文章关键词提取组件作为NLPIR的一部分,采用灵活的开发接口,可以方便地融入到用户的业务系统中,可以支持各种操作系统和各类调用语言。
以上个人见解,仅供参考!


作者:杨夕
介绍:整理自然语言处理、推荐系统、搜索引擎等AI领域的入门笔记,论文学习笔记和面试资料(关于NLP那些你不知道的事、关于推荐系统那些你不知道的事、NLP百面百搭、推荐系统百面百搭、搜索引擎百面百搭)
NLP 百面百搭 地址: https://github.com/km1994/NLP-Interview-Notes
推荐系统 百面百搭 地址: https://github.com/km1994/RES-Interview-Notes 手机版推荐系统百面百搭
搜索引擎 百面百搭 地址: https://github.com/km1994/search-engine-Interview-Notes【编写ing】
推广搜 军火库: https://github.com/km1994/recommendation_advertisement_search【 推广搜 军火库【持续更新】(微信版)】
NLP论文学习笔记: https://github.com/km1994/nlp_paper_study
推荐系统论文学习笔记: https://github.com/km1994/RS_paper_study
GCN 论文学习笔记: https://github.com/km1994/GCN_study
关注公众号【关于NLP那些你不知道的事】加入 【NLP && 推荐学习群】一起学习!!!



- 【关于 KeyBERT 】 那些你不知道的事
- 一、摘要
- 二、动机
- 三、论文方法
- 四、实践
- 4.1 安装
- 4.2 KeyBERT 调用
- 4.3 语料预处理
- 4.4 利用 KeyBert 进行关键词提取
- 参考
一、摘要
In this paper we propose a novel self-supervised approach of keywords and keyphrases retrieval and extraction by an end-to-end deep learning approach, which is trained by contextually self-labelled corpus.
Our proposed approach is novel to use contextual and semantic features to extract the keywords and has outperformed the state of the art.
Through the experiment the proposed approach has been proved to be better in both semantic meaning and quality than the existing popular algorithms of keyword extraction.
In addition, we propose to use contextual features from bidirectional transformers to automatically label short-sentence corpus with keywords and keyphrases to build the ground truth. This process avoids the human time to label the keywords and do not need any prior knowledge. To the best of our knowledge, our published dataset in this paper is a fine domain-independent corpus of short sentences with labelled keywords and keyphrases in the NLP community.
论文创新点:将 预训练模型 Bert 应用于 关键词提取
二、动机
- 文本数据量增长,关键词提取 能有效捕获 文档或句子 中的关键信息;
- 上下文语义信息对于关键词提取的重要性(the word ‘bank’ could mean a banking organisation, or it could mean river bank. Thus, context is an important aspect. );
- 传统的关键词提取方法在短文本上性能低下;
三、论文方法
- 介绍:end2end 的关键词提取方法(注:end2end 表示可以对无标注数据自标注);
- 思路:
- Domain-independent corpus collection;
- corpus cleaning;
- corpus self-labelling;
- keyword extraction model training by bidirectional LSTM.
- The self labelling stage extracted contextual features from the text by leveraging Bidirectional Transformer Encoders, and outperforms the keyword labels obtained from some of the approaches discussed above, such as RAKE [11] and TextRank [14].
四、实践
4.1 安装
pip install keybert
4.2 KeyBERT 调用
from keybert import KeyBERT
import jieba
model = KeyBERT('distiluse-base-multilingual-cased/')
4.3 语料预处理
doc = "刚刚,理论计算机科学家、UT Austin 教授、量子计算先驱 Scott Aaronson 因其「对量子计算的开创性贡献」被授予 2020 年度 ACM 计算奖。在获奖公告中,ACM 表示:「量子计算的意义在于利用量子物理学定律解决传统计算机无法解决或无法在合理时间内解决的难题。Aaronson 的研究展示了计算复杂性理论为量子物理学带来的新视角,并清晰地界定了量子计算机能做什么以及不能做什么。他在推动量子优越性概念发展的过程起到了重要作用,奠定了许多量子优越性实验的理论基础。这些实验最终证明量子计算机可以提供指数级的加速,而无需事先构建完整的容错量子计算机。」 ACM 主席 Gabriele Kotsis 表示:「几乎没有什么技术拥有和量子计算一样的潜力。尽管处于职业生涯的早期,但 Scott Aaronson 因其贡献的广度和深度备受同事推崇。他的研究指导了这一新领域的发展,阐明了它作为领先教育者和卓越传播者的可能性。值得关注的是,他的贡献不仅限于量子计算,同时也在诸如计算复杂性理论和物理学等领域产生了重大影响。」"
doc = " ".join(jieba.cut(doc))
doc
>>>
'刚刚 , 理论 计算机 科学家 、 UT Austin 教授 、 量子 计算 先驱 Scott Aaronson 因 其 「 对 量子 计算 的 开创性 贡献 」 被 授予 2020 年度 ACM 计算 奖 。在 获奖 公告 中 , ACM 表示 :「 量子 计算 的 意义 在于 利用 量子 物理学 定律 解决 传统 计算机无法 解决 或 无法 在 合理 时间 内 解决 的 难题 。Aaronson 的 研究 展示 了 计算 复杂性 理论 为 量子 物理学 带来 的 新视角 , 并 清晰 地 界定 了 量子 计算机 能 做 什么 以及 不能 做 什么 。他 在 推动 量子 优越性 概念 发展 的 过程 起到 了 重要 作用 , 奠定 了 许多 量子 优越性 实验 的 理论 基础 。这些 实验 最终 证明 量子 计算机 可以 提供 指数 级 的 加速 , 而 无需 事先 构建 完整 的 容错 量子 计算机 。」 ACM 主席 Gabriele Kotsis 表示 :「 几乎 没有 什么 技术 拥有 和 量子 计算 一样 的 潜力 。尽管 处于 职业生涯 的 早期 , 但 Scott Aaronson 因 其 贡献 的 广度 和 深度 备受 同事 推崇 。他 的 研究 指导 了 这 一新 领域 的 发展 , 阐明 了 它 作为 领先 教育者 和 卓越 传播者 的 可能性 。值得 关注 的 是 , 他 的 贡献 不仅 限于 量子 计算 , 同时 也 在 诸如 计算 复杂性 理论 和 物理学 等 领域 产生 了 重大 影响 。」'
4.4 利用 KeyBert 进行关键词提取
model.extract_keywords(doc, keyphrase_ngram_range=(1, 1))
# docs:待提取关键词 的 文档
# keyphrase_ngram_range:提取的短语,的词汇长度
# stop_words
# top_n:提取 的 关键词 数量
>>>
['计算', '计算机无法', '量子', '计算机', '物理学']
参考
- Sharma, P., & Li, Y. (2019). Self-Supervised Contextual Keyword and Keyphrase Retrieval with Self-Labelling
- KeyBERT github



所有文章
五谷杂粮
- 超1900星标!自然语言处理论文学习笔记
- 超500星标!自然语言处理 面经
- 超500星标!推荐系统 面经
- 推广搜 军火库【持续更新】
NLP百面百搭
- 【算法基础篇】
- 【关于 过拟合和欠拟合】那些你不知道的事
- 【关于 BatchNorm vs LayerNorm】那些你不知道的事
- 【关于 激活函数】那些你不知道的事
- 【关于 正则化】那些你不知道的事
- 【关于 优化算法】那些你不知道的事
- 【关于 归一化】那些你不知道的事
- 【关于 判别式(discriminative)模型 vs. 生成式(generative)模型】 那些你不知道的事
- 【机器学习篇】
- 【关于 逻辑回归】那些你不知道的事
- 【关于 支持向量机】 那些你不知道的事
- 【关于 集成学习】那些你不知道的事
- 【深度学习篇】
- 【关于 CNN】那些你不知道的事(上)
- 【关于 CNN】那些你不知道的事(下)
- 【关于 Attention 】那些你不知道的事
- 【关于Transformer】 那些的你不知道的事(上)
- 【关于Transformer】 那些的你不知道的事(中)
- 【关于Transformer】 那些的你不知道的事 (下)
- 【预训练模型篇】
- 【关于 TF-idf】 那些你不知道的事
- 【关于 Word2vec】 那些你不知道的事
- 【关于 fastText】 那些你不知道的事
- 【关于Bert】 那些的你不知道的事(上)
- 【关于Bert】 那些的你不知道的事(下)
- 【关于 Bert 源码解析I 之 主体篇 】 那些的你不知道的事
- 【关于 Bert 源码解析II 之 预训练篇 】 那些的你不知道的事
- 【关于 Bert 源码解析III 之 微调 篇 】 那些的你不知道的事
- 【关于 Bert 源码解析IV 之 句向量生成篇 】 那些的你不知道的事
- 【Bert 越大越精篇】
- 【 关于 Bert 越大越精序列】那些的你不知道的事(一)
- 【关于 Bert 越大越精序列】那些的你不知道的事(二)
- 【关于 Bert 越大越精序列】那些的你不知道的事(三)
- 【Bert 短小精悍篇】
- 【关于 Bert 压缩】 那些你不知道的事
- 【关于 BERT to TextCNN】那些你不知道的事
- 【关于 FastBERT 实现】那些你不知道的事
- 【关于自训练 + 预训练 = 更好的自然语言理解模型 】 那些的你不知道的事
- 【文本分类篇】
- 【关于 文本分类】那些你不知道的事
- 【关于 文本分类 trick】那些你不知道的事
- 【其他】
Rasa 对话系统
- 《【社区说】一起来聊聊 Rasa 3.0》 不完全笔记
- (一)对话机器人概述
- (二)RASA开源引擎介绍
- (三)RASA NLU语言模型
- (四)RASA NLU分词器
- (五)RASA NLU特征生成器
- (六)RASA NLU意图分类器
- (七)RASA NLU实体提取器
- (九)RASA自定义pipeline组件
- (十)RASA CORE Policy
- (十一)RASA CORE Action
- (十二)RASA Domain
- (十三)RASA 训练数据
- (十四)RASA story
- (十五)Rasa Rules
- (十六)RASA最佳实践
- (十七)基于RASA开始中文机器人
- (十八)基于RASA开始中文机器人实现机制
- (十九)基于知识图谱的问答系统(KBQA)
- (二十)基于阅读理解的问答系统
- (二十一)RASA应用常见问题
- (二十二)RASA的超参数优化
- (二十三)机器人测试与评估
- (二十四)利用Rasa Forms创建上下文对话助手
- DIET:Dual Intent and Entity Transformer——RASA论文翻译
知识图谱入门
- 浙大图谱讲义 | 第一讲-知识图谱概论 — 第1节-语言与知识
- 浙大图谱讲义 | 第一讲-知识图谱概论 — 第2节-知识图谱的起源
- 图谱讲义 | 第一讲-第3节-知识图谱的价值
- 图谱讲义 | 第一讲-第4节-知识图谱的技术内涵
- 图谱讲义 | 第二讲-第1节-什么是知识表示
转载记录
- Bert与TensorRT部署手册,享受丝滑的顺畅
- 句向量新方案CoSENT实践记录
- CHIP2021|临床术语标准化第三名方案开源
- CHIP2021 | 医学对话临床发现阴阳性判别任务第一名方案开源
- 破解transformer八股,快问快答
- BERT可视化工具bertviz体验
- PRGC:一种新的联合关系抽取模型
- 给神经网络加入先验知识!
- CBLUE中文医学语言理解测评Baseline

可参考下面几种做法,如果能拿到点击日志时,效果相比于其他方法是比较好的

TFidf 、textrank 、实体词识别等等

keyBert网站: KeyBERT
工程代码: https://github.com/MaartenGr/KeyBERT
1、实现思路
keyBert是一种基于BERT的极简关键词提取方法,整体实现思路比较简单。关键词提取是通过查找文档中与文档本身最相似的词来完成的。首先,用BERT提取文档嵌入,得到文档级表示。然后,提取N-gram单词/短语的单词嵌入。最后,使用余弦相似性来查找与文档最相似的单词/短语。 那么,最相似的词可以被识别为最能描述整个文档的词。
KeyBERT的提取关键词的过程可以分为以下几个步骤:
- 文本预处理:首先,KeyBERT对输入的文本进行预处理。它会将文本转换为小写,并去除一些常见的停用词和标点符号,以减少噪音对关键词提取的影响。
- 文本编码:接下来,KeyBERT使用预训练的BERT模型对预处理后的文本进行编码。BERT模型将每个词转换为对应的词向量,并将整个句子编码为一个固定长度的向量表示。这个向量表示保留了词与词之间的上下文信息,可以更好地表达句子的语义。
- 关键词提取:最后,KeyBERT使用余弦相似度来查找与文档最相似的词/短语。可以将最相似的词/短语定义为最能描述整个文档的词/短语。
2、使用BERT进行中文关键词提取
(1)安装keyBert
pip install keybert(2)提取中文关键词
文本转化成词共现矩阵
from sklearn.feature_extraction.text import CountVectorizer
import jieba
def tokenize_zh(text):
words = jieba.lcut(text)
return words
vectorizer = CountVectorizer(tokenizer=tokenize_zh)(3)提取关键词
from keybert import KeyBERT
kw_model = KeyBERT()
# KeyBERT 0.4.0中,model默认的是 paraphrase-MiniLM-L6-v2,
# KeyBERT 0.6.0中,model默认的是 all-MiniLM-L6-v2
doc = "我爱北京天安门"
keywords = kw_model.extract_keywords(doc, vectorizer=vectorizer)
输出结果
[('天安门', 0.7936), ('北京', 0.64), ('我', 0.5716), ('爱', 0.4095)]
导读:本文是“数据拾光者”专栏的第六十篇文章,这个系列将介绍在广告行业中自然语言处理和推荐系统实践。本篇从理论到实践介绍了超好用的无监督关键词提取算法Keybert,对于希望使用无监督学习算法抽取关键词的小伙伴可能有帮助。
欢迎转载,转载请注明出处以及链接,更多关于自然语言处理、推荐系统优质内容请关注如下频道。
知乎专栏:数据拾光者
公众号:数据拾光者
摘要:本篇从理论到实践介绍了超好用的无监督关键词提取算法Keybert。首先介绍了调研背景;然后重点介绍了什么是Keybert、KeyBERT提取关键词流程和如何通过MSS和MMR算法解决多样性问题;最后从实践的角度介绍了KeyBERT的安装、使用以及影响效果的因素。对于希望使用无监督学习算法抽取关键词的小伙伴可能有帮助。
下面主要按照如下思维导图进行学习分享:

01 背景介绍
最近在做关键词抽取项目,需要将用户搜索query、资讯news、广告文案、用户点击title等不同场景下的文本数据提取关键词,然后作为特征提供给下游召回和推荐场景中使用。之前也分享过一篇关键词抽取的文章
关键词抽取流程主要分成获取候选词和候选词打分两个流程:
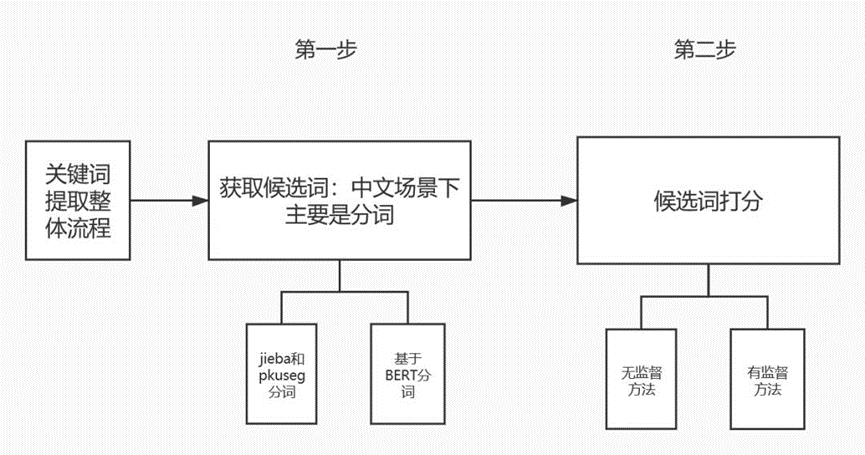

对于获取候选词流程,中文场景下主要是分词,一方面我们主要通过jieba和哈工大pkuseg分词,另一方面还可以通过BERT进行分词;
对于候选词打分流程,主要通过无监督学习和有监督学习两大类进行打分。
最近调研到Keybert作为一种无监督学习的关键词抽取流程,效果不错,这里对Keybert进行调研并打算应用到广告场景中。
02 Keybert详解
2.1 什么是Keybert
Keybert是一种基于无监督学习的关键词抽取技术,不仅效果好,而且易于使用。Keybert主要通过Bert获取文档和候选词的embedding,然后使用余弦相似度计算得到文档中最相似的候选词作为关键词。
2.2 Keybert提取关键词流程
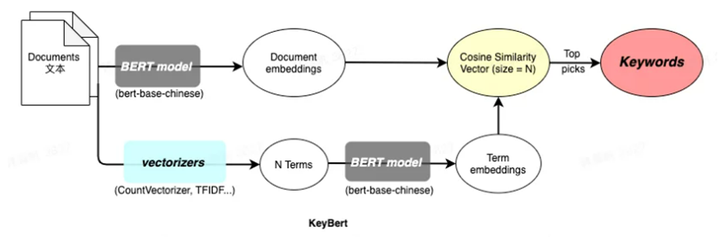

Keybert提取关键词流程如上图所示,主要包括三个流程:
第一步,使用Bert获取文档/候选词的embedding表示;

这里需要注意的是文档embedding质量的好坏会影响关键词抽取的结果。Keybert支持从sentence_transformers、Flair、Hugginface Transformers、spaCy等下载预训练模型对文档进行embedding编码;
第二步,使用词嵌入模型提取n-gram词或者关键词作为候选词,这里可以是sklearn中的CountVectorizer或者Tfidf等方法;
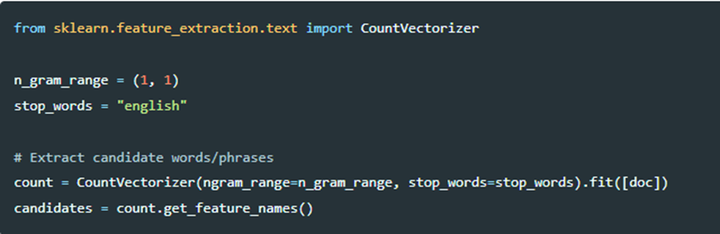

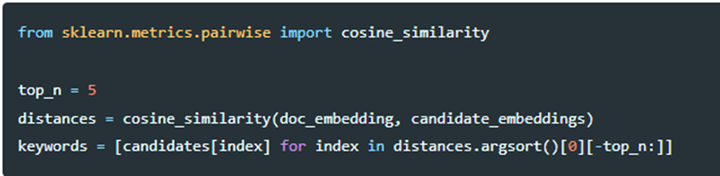
第三步,计算文档和候选词的余弦相似度,找到最能表示文档的关键词。

2.3 Keybert如何解决多样性问题
了解了Keybert提取关键词的流程后,下面通过一个实际的例子查看Keybert抽取效果,同时了解下作者是如何解决多样性问题。使用下面的英文文档:


使用Keybert抽取top5的候选关键词结果如下:


上面抽取的5个候选关键单词可以很好的代表文档内容即有监督学习定义。相比于单词,我们还可以抽取词组作为候选关键词,把n_gram_range设置成(3,3)则可以使用3个单词组成的词组作为候选关键词,抽取结果如下:


虽然使用3-gram词组相比于单个词来说更能代表关键词,但是存在的问题是词组之间十分相似。Keybert的作者认为词组之间比较相似主要原因在于这些词是最能代表文档的关键词, Keybert主要通过MSS(Max Sum Similarity)和MMR(Maximal Marginal Relevance)两种算法来提升关键词的多样性。
2.3.1 Max Sum Similarity算法
MSS算法思想是先找到topN相似的单词或词组作为候选词nr_candidates,然后从nr_candidates中找到最不像的topK作为候选关键词。MSS算法实现代码:
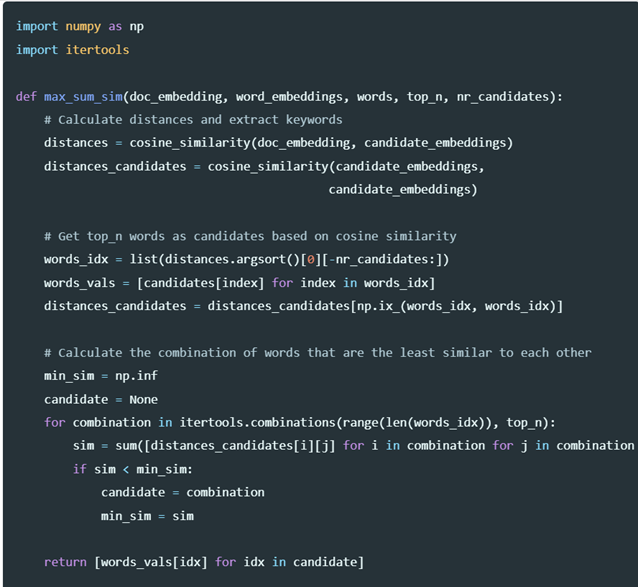

通过MSS可以提升抽取关键词的多样性,当MSS中的nr_candidates设置过小时基本和余弦相似度结果类似,基本失去作用;但是当nr_candidates设置过大时则容易导致提取关键词不准。下面是MSS中的nr_candidates的对关键词抽取结果影响:


2.3.2 Maximal Marginal Relevance算法
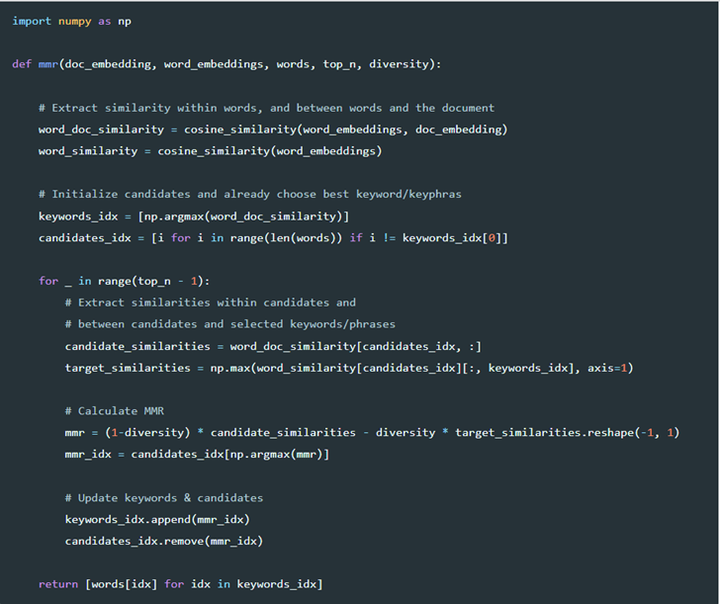
MMR最大边缘相关算法目的一方面是减少排序结果的冗余,另一方面保证结果的相关性。最早应用于文本摘要提取和信息检索等领域,在推荐场景下体现在给用户推荐相关商品的同时,保证推荐结果的多样性,即排序结果存在着相关性与多样性的权衡。MMR的核心思想是找到和文档Q最相似同时和其他候选关键词Dj最不相似的候选词Di作为关键词。下面是MMR的计算公式:
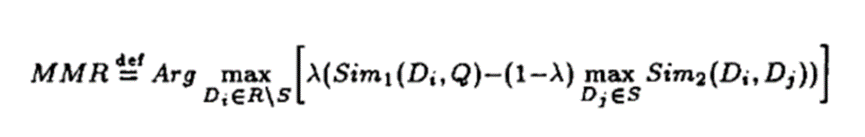

MMR算法实现代码如下:

通过参数diversity来控制多样性,如果参数值设置过低则和相似度计算结果差不多。下面分别是设置diversity为0.2和0.7时关键词抽取效果:


03 实战Keybert
上面从理论方面详细介绍了Keybert算法,下面从代码实践的角度介绍Keybert。
3.1 Keybert安装
pip install Keybert3.2 Keybert使用
通过下面的代码可以构建Keybert模型:
from Keybert import Keybert
kw_model = Keybert(model="paraphrase-multilingual-MiniLM-L12-v2")
keywords = kw_model.extract_keywords(doc, keyphrase_ngram_range=(3, 3),
stop_words='english', use_mmr=True, diversity=0.7)Keybert主要的参数是预训练模型,在0.4.0版本默认“paraphrase-MiniLM-L6-v2”,在0.6.0版本模型是“all-MiniLM-L6-v2”。需要注意的是0.6.0版本还支持Hugginface Transformers库的预训练模型。
抽取关键词的方法是extract_keywords函数,函数说明如下图所示:
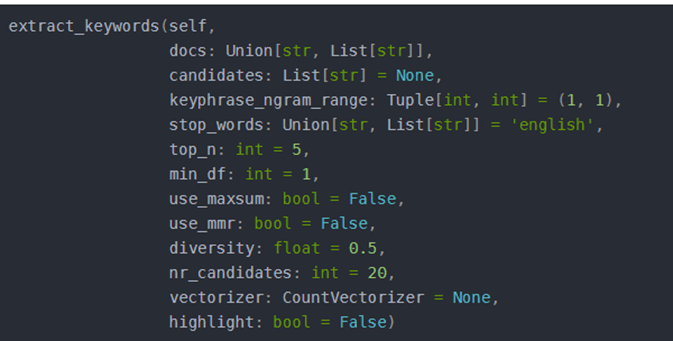

extract_keywords主要有以下参数:
- docs:要提取关键字/关键短语的文档
- candidates:要使用的候选关键字/关键短语,而不是从文档中提取它们
- keyphrase_ngram_range:提取的关键字/关键短语的长度(以字为单位)
- stop_words:要从文档中删除的停用词
- top_n:返回前 n 个关键字/关键短语
- min_df:如果需要提取多个文档的关键字,则一个单词在所有文档中的最小文档频率
- use_maxsum: 是否使用 Max Sum Similarity 来选择keywords/keyphrases
- use_mmr:是否使用最大边际相关性(MMR)进行关键字/关键短语的选择
- diversity:如果 use_mmr 设置为 True,结果的多样性在 0 和 1 之间
- nr_candidates:如果 use_maxsum 设置为 True,要考虑的候选数
- vectorizer:从 scikit-learn 传入你自己的 CountVectorizer
- highlight:是否打印文档并突出显示其关键字/关键短语。注意:如果传递了多个文档,这将不起作用。
函数返回文档的前 n 个关键词及距离得分。
3.3 Keybert效果影响
3.3.1 编码器优化
影响Keybert效果的一个主要因素是编码器质量,编码器效果的好坏会影响相似度距离得分,从而影响排序,导致最终关键词抽取结果差别很大。Keybert支持以下多种模型作为编码器:
- Sentence-Transformers
- Flair
- Spacy
- Gensim
- USE
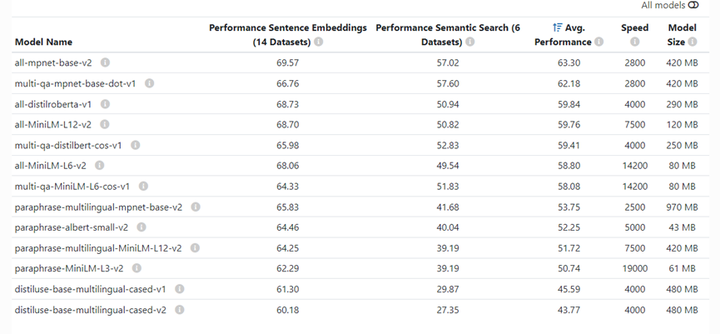
(1) 使用SentenceTransformers

Sentence Transformer调用方法如下所示:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(model='model_name')如何选择Sentence Transformers预训练模型?如果需要高质量并且性能好的模型可以使用“paraphrase-mpnet-base-v2”;如果是英文场景则可以使用“paraphrase-MiniLM-L6-v2”;如果是多语言场景则可以使用“paraphrase-multilingual-MiniLM-L12-v2”。
(2) 使用Hugginface Transformers
Huggingface Transformers预训练模型地址如下: https://huggingface.co/models

Hugginface Transformers调用方法如下图所示:
bert_model_path = “/data/chinese_roberta_L-2_H-128”
kw_model = Keybert(model= bert_model_path)(3)使用Flair模型
Keybert还支持Flair模型调用,使用方式如下:
from Keybert import Keybert
from flair.embeddings import TransformerDocumentEmbeddings
roberta = TransformerDocumentEmbeddings('roberta-base')
kw_model = Keybert(model=roberta)3.3.2 针对中文场景的ZhKeybert
ZhKeybert是针对中文场景进行优化的Keybert,ZhKeybert开源项目地址如下:
https://github.com/deepdialog/ZhKeyBERT
(1) ZhKeybert的安装
git clone https://github.com/deepdialog/ZhKeybert
cd ZhKeybert
python setup.py install –user(2) ZhKeybert的实践
from zhKeybert import Keybert, extract_kws_zh
docs = """时值10月25日抗美援朝纪念日,《长津湖》片方发布了“纪念中国人民志愿军抗美援朝出国作战71周年特别短片”,再次向伟大的志愿军致敬! """
kw_model = Keybert(model='paraphrase-multilingual-MiniLM-L12-v2')
extract_kws_zh(docs, kw_model)ngram_range决定了结果短句可以由多少个词语构成:


(3) ZhKeybert优化项
ZhKeybert对Keybert的主要改进有:
- 细化候选关键词的筛选,避免跨句组合等情况;
- 调整超参数,寻找效果较优的组合(例如原始模型中use_maxsum的效果奇差);
- 找出效率和效果均比较优秀的模型paraphrase-multilingual-MiniLM-L12-v2。
总结及反思
本篇从理论到实践介绍了超好用的无监督关键词提取算法Keybert。首先介绍了背景;然后重点介绍了什么是Keybert、KeyBERT提取关键词流程和如何通过MSS和MMR算法解决多样性问题;最后从实践的角度介绍了KeyBERT的安装、使用以及影响效果的因素。对于希望使用无监督学习算法抽取关键词的小伙伴可能有帮助。
参考资料
[1] Keyword Extraction with BERT: https://grootendorst.netlify.app/blog/Keybert/
[2] https://github.com/deepdialog/ZhKeyBERT
[3] https://github.com/MaartenGr/KeyBERT


关于关键词提取,写了一些自己的感想,参考链接: 关键词提取 A Quick Review

看你主要提取什么文本的关键词,曾经在微博上试过TF-IDF,LDA 和TextRank,感觉LDA在短文本上完全不靠谱,在文档级应用上应该可以(没试过,这方面的论文应该很多)。

主要有抽取式和生成式,比如AdaSeq里就实现了抽取式的一些方法。下面是AdaSeq序列理解技术专栏的关键词技术报告~
《篇章级关键词抽取模型开箱即用,并提供一键式模型训练、部署。》
作者:映辉
本文介绍下最近开源的框架 AdaSeq中集成了关键词提取的模型和代码。
我们从alimeeting的654场会议内容作为文档,对每篇会议文档找了三名标注人员进行关键词抽取标注,然后将每个在文中的关键词标注为进行NER的格式,在bert-crf的框架上当做NER任务进行训练。训练好的模型已经开源在modelscope上,安装modelscope,采取ner pipeline,调用我们训练好的baseline model,就可以使用了。

ModelScope 魔搭社区
快速使用
modelscope上已经提供了采用alimeeting的数据、structbert为backbone训练好了的模型,并进行了封装。简单使用方法如下:
先安装modelscope
pip install "modelscope[nlp]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html接下来就可以调用接口在自己的数据上测试
from modelscope.pipelines
import pipeline
from modelscope.utils.constant import Tasks
ner_pipeline = pipeline(Tasks.named_entity_recognition, 'damo/nlp_structbert_keyphrase-extraction_base-icassp2023-mug-track4-baseline')
result = ner_pipeline('我的名字叫做张小明,我们根本不喜欢今天的晚会,今天的晚会很不好。') print(result)
# {'output': [{'type': 'KEY', 'start': 20, 'end': 22, 'span': '晚会'}, {'type': 'KEY', 'start': 26, 'end': 28, 'span': '晚会'}]}可见在随便的一句话中,zero-shot的识别效果也还不错。一些模型、指标等细节可以访问modelscope链接 https://modelscope.cn/models/damo/nlp_structbert_keyphrase-extraction_base-icassp2023-mug-track4-baseline/summary
===============================分界线==============================
使用AdaSeq自主训练
想尝试用 AdaSeq,在自己的数据集上train一个关键词抽取模型的小伙伴,可以往下看。
数据下载
以Alimeeting的数据集为例。(训练集数据可以在 关键词抽取train集上下载)数据格式:
将csv的每条数据转化为json,所有数据构成一个json列表。


其中我们关心的key是sentences和candidate。sentences是单条数据中会议的每句话,candidate是关键词标注(key_word)和关键词所抽取的句子来源(key_sentence)。
代码下载
git clone代码。
git clone https://github.com/modelscope/adaseq.git pip install -r requirements.txt -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html数据处理
我们的模型处理数据的格式是conll格式,某个关键词的头采用B-KEY的tag,关键词的其他部分采用I-KEY的tag,其余不涉及关键词的token打上O,具体demo如下:
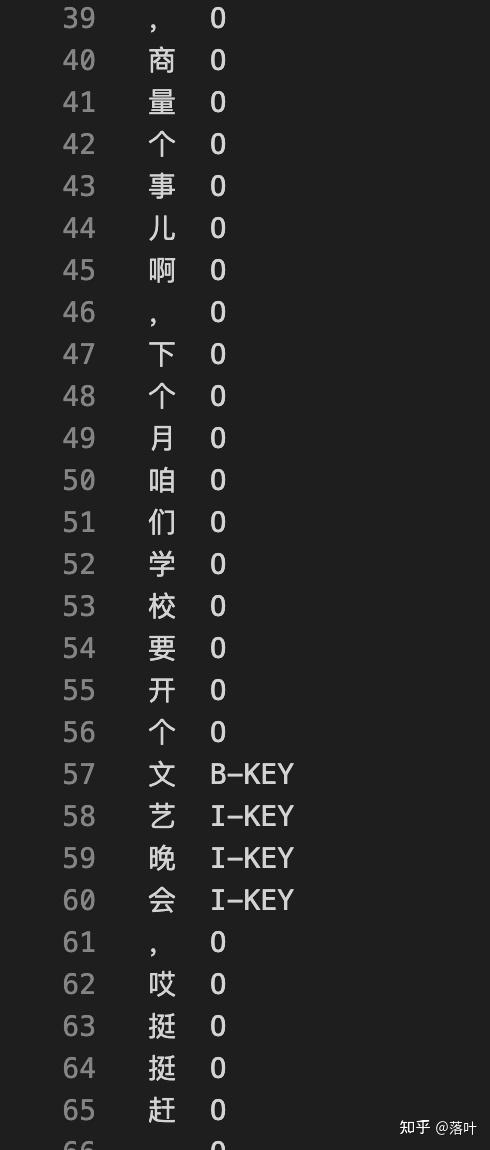

由于一篇文档长达1.7w个token,直接送入模型中对显存要求较高,而且除了deberta等,大多数的PLM不支持这么长的token序列,所以我们要做切割。我们保证同一句话的每个token是在同一个batch中的,所以可以将一些句子按照指定长度附近拼接为一个小文档。比如我们设置max_size是192,就可以将其中的六七句话拼接到一起,作为小文档,在后面接上\n\n 。
数据处理可以直接使用内部代码
cd examples/ICASSP2023_MUG_track4
python preprocess.py序列标注模型框架
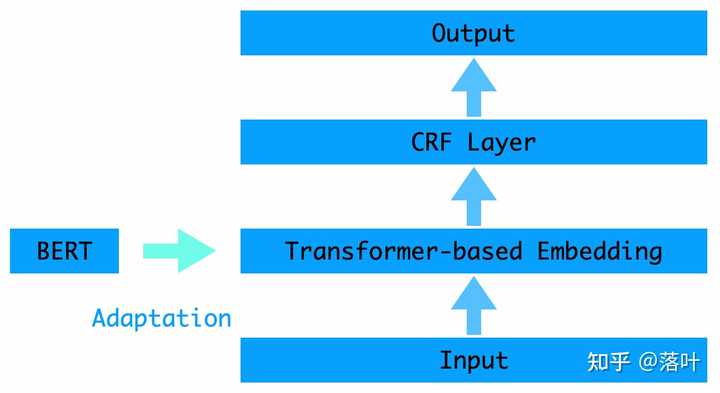

AdaSeq提供基础的序列标注模型是BERT CRF,通过将关键词转成标签序列,模型学习输入文本到标签序列的mapping,这里BERT可以有效建模中文文本字与字之间上下文的关系,CRF有效建模标签之间的关系。当然,AdaSeq里也提供了更多丰富的组件,可以进一步优化和尝试,
模型训练配置
在AdaSeq框架下,可以直接通过配置yaml文件,来进行训练模式的调整,设计训练模型的backbone(struct-bert等)、模型架构(bert-crf等)、数据集目录、任务类型(sequence-labeling等),在该任务下的配置文件如下:
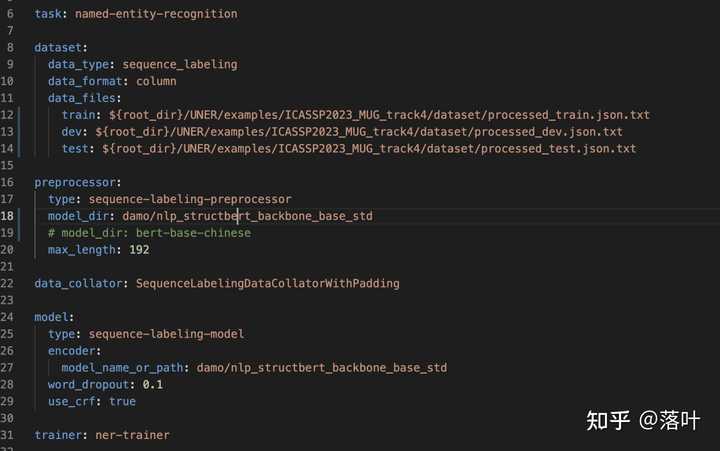

之后直接在项目根目录下,运行scripts/train.py,指定配置文件为bert_crf_sbert.yaml即可开始训练
python scripts/train.py -c examples/ICASSP2023_MUG_track4/configs/bert_crf_sbert.yaml训练模型的过程中会打印dev集上NER的评估结果,以及将预测结果写入对应的输出文件pred.txt。
评估指标
关键词的评估指标和NER并不完全相同,其最终需要提取的是关键词的集合和真正关键词的重合之间的关系,而并不取决于每个位置的BIOtag识别的正误。主要有exact matched 和partial matched两种metrics进行评估。
- exact matched:是指评估一个关键词是否正确是取决于一个词是否出现在标注关键词中,一个词算作正确当且仅当与标注关键词集合中的某个完全一致的情况,如“文艺晚会”和“文艺晚会”
- partial matched:一个词算作正确,只需要其与标注关键词集合中的某个词有超过2大小的公共子串即可,如“文艺晚会”和“晚会”
此外,为了减缓模型overgenerate关键词的情况,我们还根据提取出的关键词在文档中的词频来进行排序,选取出top@10,top@20,作为答案进行评估。
在adaseq的关键词抽取模块ICASSP2023_MUG_track4中,也集成了对于全量关键词、top@10、top@20的关键词采用exact matched和partial matched的评估函数,运行脚本即可:
cd examples/ICASSP2023_MUG_track4
python evaluate_kw.py dataset/dev.json ${root_dir}/experiments/kpe_sbert/outputs/${datetime}/pred.txt dataset/split_list_dev.json evaluation.log输出的评估指标会写入evaluation.log中。
==========================分界线=============================
欢迎小伙伴们到 ModelScope 魔搭社区上了解其他的模型和数据哦,可以基于 AdaSeq完成一键进行训练和推理哦~
如对序列理解领域相关技术比较感兴趣的小伙伴,或者使用AdaSeq训练框架遇到技术问题,可以扫描钉钉群(4170025534)交流哈~
更新下:后来尝试了用NER(命名实体识别)的框架来做关键词抽取,其实就是典型的序列标注问题,用lstm,每个时间步都输出,是关键词输出1,非关键词输出0。至少是能跑,但这个精度上好像不是很理想,这可能和数据集有关,数据集太少了才1000条。。
----------------------------------------------------------------
看了各位前辈的回答,发现关键词抽取要么是无监督的tfidf,textrank等,要么有监督都是基于特征的传统机器学习分类算法。
现在深度学习这么热,怎么没见过用深度学习做关键词抽取的?比如把文本词向量化,然后用lstm去一个词一个词识别,是的话输出1,不是的话输出0. 各位前辈有这方面的相关内容推荐给我看看,谢啦

说点自己的见解~
首先,这个题目可大可小,脱离了具体的应用场景,“关键”就变得难以界定。从当前大多数答案看来,默认的场景是在大量的文本中,抽取代表这些文本的词语,多数技术是以“词频”统计信息作为基础,那么就默认了以“常见”作为“关键”的定义,当然TFIDF等算法平滑了极高频带来的干扰。
其次,问题还需要进一步的界定,关键词抽取的范围是什么,是针对单个文本抽取还是针对一个数据集。TFIDF显然是针对一个数据集下的单个文档的关键词抽取,这样提取出来的关键词就不一定能代表整个数据集了。提这里是因为曾经见过算法工程师搞不清TFIDF的统计口径,例如一个这样的任务,在一个类型的电影影评中抽取这个类型电影的关键词,默认单个影评作为统计单位(TF的取值范围),那么TFIDF能做好的是对每个影评抽取关键词,而不是代表这个电影类型的关键词。假如区分度是“关键”的一个指标,还是影评的例子,可以是某个类型电影影评的合集作为一个统计单位,然后数据集的范围是N个类型的影评,这样TFIDF在单个类型数据中排序所获得的关键词,就具有了代表该类型的意义。(这个例子不太恰当的地方在于电影类型不足够多,那么统计会失去意义)。
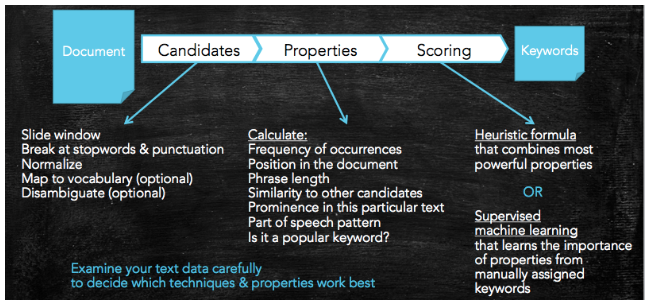
上述是关键词提取任务的常见理解,基本的方案和流程可以整理为:
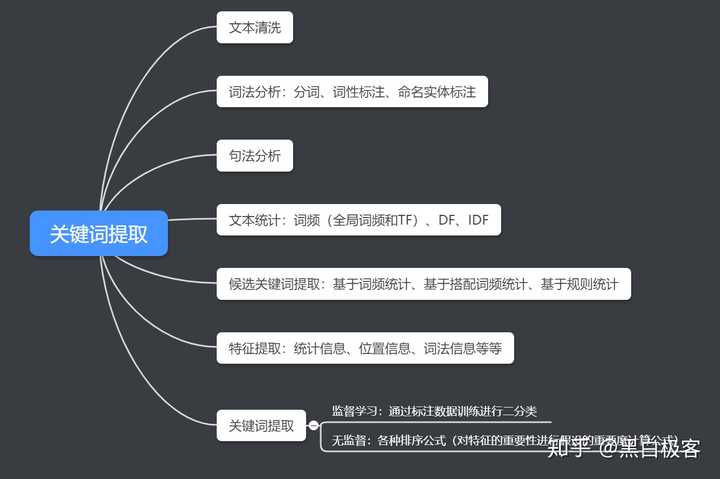

然而,实际中上述的方案我通常是用在文本分析阶段,用于了解语料和构建词典,不会接入到具体的应用的流程中。
我认为关键词提取其实无处不在,比如命名实体识别,这也可以认为是关键词提取,只不过提取的是句子中核心的重要成分。因此从应用角度来说,关键词提取应该说没有固定的方案,在不同的应用阶段,"关键"的定义都会变化,就需要不同的方案来适应。初始的阶段"关键"就是提取核心主干,去掉不重要的成分。主题分析阶段关键词就是主题词。情感分析阶段关键词就是情感词。
综上,"关键"的定义决定了提取方案。