Often times, you will find webmasters and bloggers referencing to a something called “Robots.txt” file which you can use to achieve different objectives with respect to indexing and crawling by search engines. In this article, we will learn what this Robots.txt file is and how you can use it to optimize your website for search engines and better crawling or indexing.
If you are not aware of the terms – “Crawling” and “Indexing”, do check out our SEO glossary or read our earlier article on – “What is Crawling and Indexing?” to understand how search engines crawl and index content on your website. Unless you know how Search engines crawl and discover your content, you will not clearly understand the purpose of using a Robots.txt file on your website or blog.
What is Robots.txt?
Robots.txt is a simple text file placed at the root of your website or blog which tells search engines which pages or sections to crawl and which pages and sections not to crawl. The Robots.txt file can also be used to define which search engines are allowed to crawl and index your content and which search engines are not allowed to crawl and index the content of your website.
So using the Robots.txt file you can set access permissions for different search bots, spiders and give them directives on which pages and sections of your website they are allowed to crawl and index and which ones they aren’t allowed to index.
Please note that Robots.txt is not a mandatory requirement for each and every website.
If your website or blog does not have a robots.txt file, it is perfectly all right. You don’t need to worry about it too much as not having a Robots.txt file will not harm your website or blog in any way. It’s just that having a Robots.txt file is considered good because it allows you to communicate with search bots and give them some directions. At the same time, not having a Robots.txt file is not considered bad or having some sort of drawback.
Does your Website Need a Robots.txt file?
Now how do you figure out whether your website needs a Robots.txt file or not?
Here are a few questions to ponder upon
- Do you want to hide some part of your website from search engines and do not want search engines to show the content of those pages or sections on search result pages?
- Do you want to prohibit specific search engines from crawling the content of your website? For example,. you do not want Yahoo.com to index and crawl your website content for some reason.?
- Do you want to restrict search engines from crawling specific file types on your website? For example, your website has a lot of PDF documents which you do not want to disclose to the public and you want those URL’s not to show up in search results? However, you do want the other pages to show up when searched for, it’s just that you don’t want only PDF files to be crawled or indexed?
- Do you want to restrict search engines from crawling and indexing image content on your website?
- Is your website is managed by a content management system and there are sections of your website which you don’t want search engines to crawl and index? Is there a large part of your website which is undergoing temporary maintenance and you want search engines not to crawl that particular section for the time being?
If “YES” is the answers to any of the above questions, you need a Robots.txt file placed at the root section of your website or domain name. If “NO” is the answer to all of the above questions, you do not need a Robots.txt file and can safely ignore it.
Please note
Not having a Robots.txt file on your website will not harm your site in any way.
However, having a Robots.txt file and configuring it badly or putting in some code which you do not understand may harm your website. You have to know what you are doing with Robots.txt file.
If configured in a wrong way, a misconfigured Robots.txt file can cause severe damage to your website although that damage can be repaired by changing the code in the Robots.txt file and replacing it with the correct one.
How to Create a Robots.txt file?
Creating a Robots.txt file is super easy and super difficult, depending on how complex your site is and how complex your requirement for blocking a specific part of your website is.
If you have a simple requirement that you want to block a particular folder from search engines, then it will probably take less than 5 minutes to get it done. However, if your website is fairly big and there are lots of things that has to be defined, then the Robots.txt file can get really big and really complex. For example, have a look at Google’s robots.txt file, it’s pretty big and there are lines and lines of code giving a directive to search engines on what to crawl and what not to crawl.
Here is how you create a Robots.txt file
Open a simple text editor program and paste the following code
User-agent: *
Allow: /
Before you go any further, you need to know the meaning of that code which you just put in the Robots.txt file
User-agent:聽This means the Bot or source whom you are setting the directive for. If you want to only block Google from specific portions of the site, your Robots.txt file should look like the following
User-agent: Googlebot
Disallow: /products/
What this means is that you are telling Googlebot not to crawl or index the /products/ subfolder in your website.
If you want to tell all the search engines not to crawl or index the “Products” subfolder in your website, you should use “*” instead of a specific Bot. This tells everyone to ignore that specific folder or directory from indexing.
A聽 Robots.txt Blunder You Should Look Out For
While you are learning SEO, just look out for this horrible blunder which will block all search engines from accessing the content of your website.
User-agent: *
Disallow: /This should be avoided because what you are telling search engines is that do not index anything on my website and do not crawl or look for information on my website. Also, do not show any of what you have crawled in your search result pages.
If you put this in your Robots.txt file, suddenly your site’s pages will disappear from Google search results and you will not see any traffic coming in. This could be a total disaster for your online business, so watch out for this pitfall.
For advanced commands on Robots.txt, please visit the Web Robots database which lists information about all the web bots, search spiders, and crawlers which routinely visit a different website to crawl and find information. From this web robots database, you will be able to find a particular crawler, learn more about it and then decide whether you want this crawler to crawl the content on your site or whether you want to block this crawler from accessing content on your website.
Location of Robots.txt file
One very important thing to note is that no matter in which directory your website is installed, the robots.txt file is always placed at the root of your domain name.
Let’s take a couple of examples.
Let’s say you have a website – www.example.com and you have a blog for this website at www.example.com/blog/. You are using WordPress as your content management system for the blog and all the files for the blog are placed under the www.example.com/blog/ directory.
Similarly, let’s say you have an e-commerce store under www.example.com/store/, a blog under www.example.com/blog/ and a forum under www.example.com/forum/. All three folders use different software for their management, development and content creation or site management.
But there will be only one Robots.txt file for the entire domain and no specific robots.txt file for each folder or directory.
The robots.txt file would be for the domain – www.example.com and not for the Blog folder or any other folder. A robots.txt file is associated with a domain name and not individual folders, directories, or subdomains. No matter where the website is installed in a domain name, the robots.txt file is always placed at the root of your domain name (right in the public_html folder)
Test Your Robots.Txt File
After you have created the Robots.txt file for your website, you should use Google’s Robots.txt tester to test the Robots.txt file.
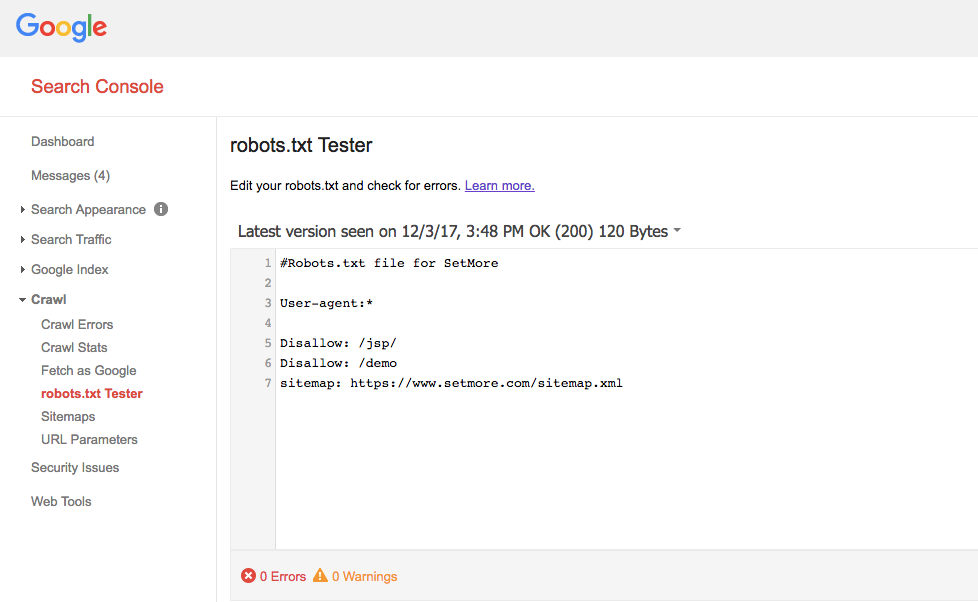
This tool will test your robots.txt file and show you errors and warnings if any. It is a good way to figure out if the code that you have put in the robots.txt file contains any errors or not.
Please note that the code that you put in Robots.txt file is just a directive only, it cannot enforce crawler behavior on your site because it is up to the crawler to honor your request. There are situations when you may have blocked a specific file in Robots.txt but it will continue to appear in search engines because there is either an external link to that page or there is some other way the crawler has discovered that content and it will continue to show up on search results, no matter whether you block it in your Robots.txt file.
In those situations, Google suggests you either password protect that file on your server, delete it or noindex it with a meta tag for that particular page. Learn more on Robots.txt from Google Webmaster Help support article.
Be Sure to read our SEO Guide which contains useful information about SEO and we have discussed in detail key SEO Concepts with examples.